
Spidering a web application using website crawler software in kali linux
There are lots of tools to spider a web application (an companies which are based on this tech, eg google) short list of tools to help you spider a site (eg for creating a sitemap for SEO, or recon for a pentest or loging to define your attack surfaces)
1) screaming frog
screaming frog is a well known tool in the SEO industry, it has a pretty UI and will spider a site and find all the urls (it also provides other information that may be of use, eg redirect codes, url parameters, etc)

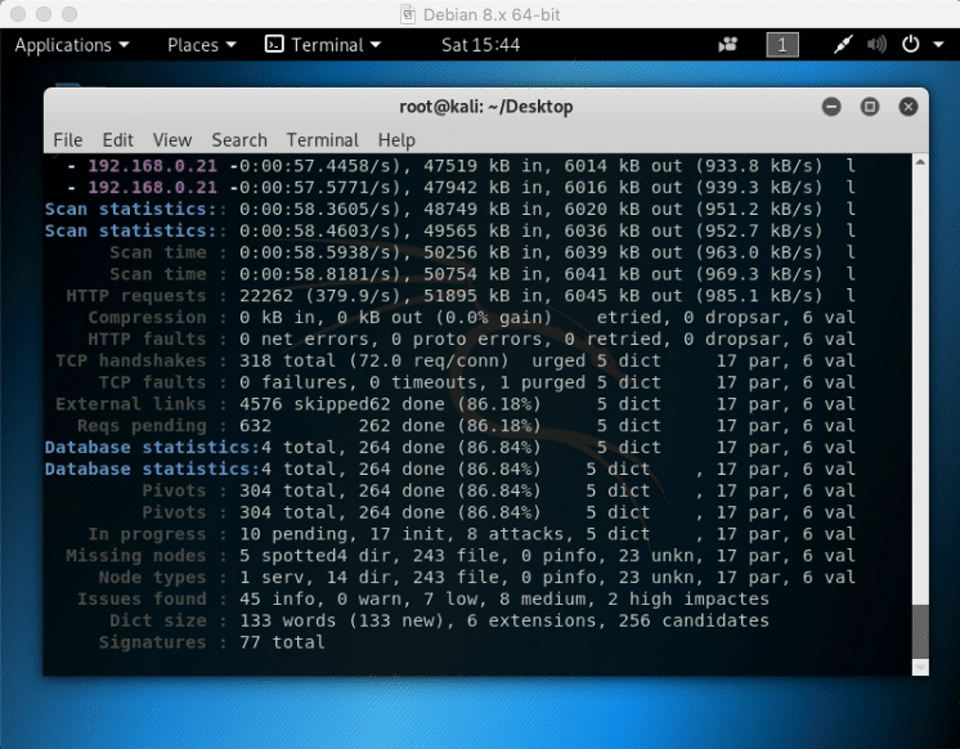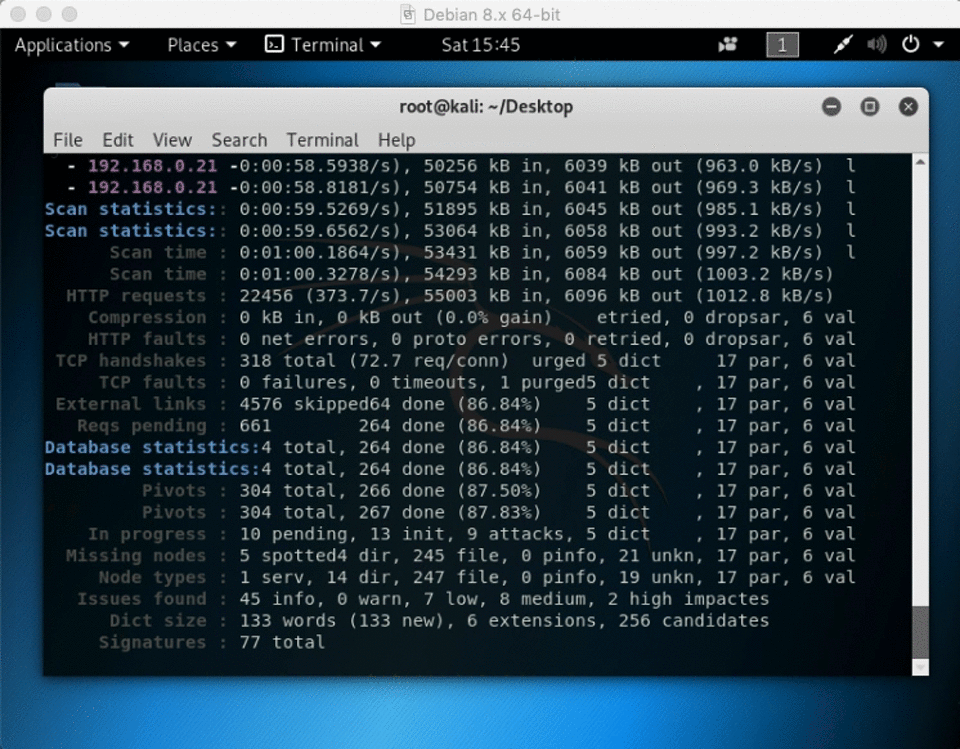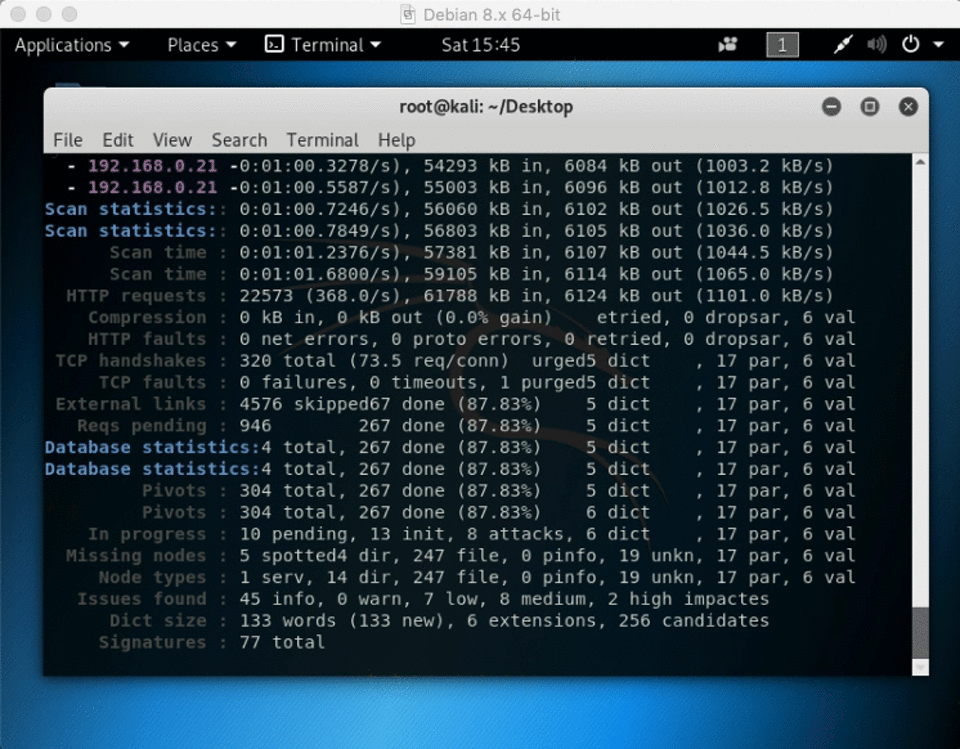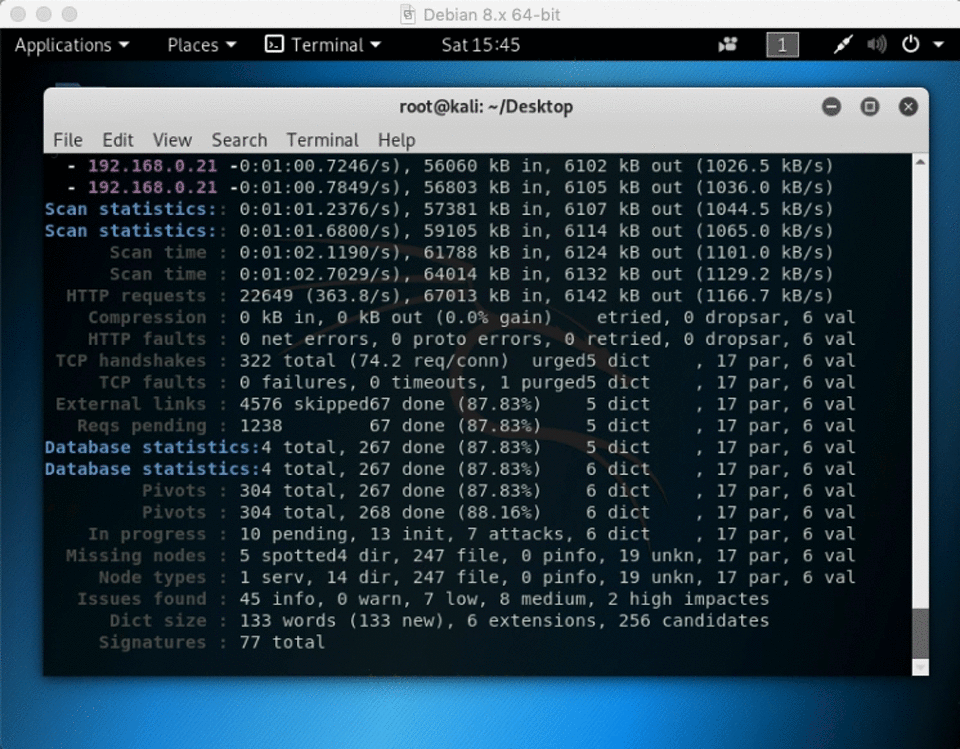
2) website crawler software kali Linux ( skipfish
skipfish -YO -o ~/Desktop/folder https://192.168.x.x
skipfish is included in kali linux and will spider a site for you (and can also test for various vulnerable parameters and configurations) – using the -O flag will tell skipifsh not to submit any forms, and -Y will tell skipfishn not to fuzz directories
https://tools.kali.org/web-applications/skipfish
3) grabber
grabber --spider 1 --sql --xss --url https://192.168.x.x
grabber can spider and test for sqli and xss.
It’s a very basic tool, and is only recommended for small sites.
Features:
Cross-Site Scripting
SQL Injection (there is also a special Blind SQL Injection module)
File Inclusion
Backup files check
Simple AJAX check (parse every JavaScript and get the URL and try to get the parameters)
Hybrid analysis/Crystal ball testing for PHP application using PHP-SAT
JavaScript source code analyzer: Evaluation of the quality/correctness of the JavaScript with JavaScript Lint
Generation of a file [session_id, time(t)] for next stats analysis.
4) website crawler software kali Linux – metasploit:
use auxiliary/crawler/msfcrawler msf auxiliary(msfcrawler) > set rhosts www.example.com msf auxiliary(msfcrawler) > exploit you might want to check my metasploit posts
5) httrack
httrack https://192.168.x.x –O ~/Desktop/file
httrack will mirror the site for you, by visiting and downloading every page that it can find. Sometimes this is a very useful option.
6) burp suite
Burpsuite has a spider built in, you can right-click on a request and ‘send to spider’
7) wget -r
wget -r https://192.168.x.x
wget can recursively download a site (similar to httrack)
https://www.gnu.org/software/wget/manual/wget.html#Recursive-Retrieval-Options
GNU Wget is capable of traversing parts of the Web (or a single HTTP or FTP server), following links and directory structure. We refer to this as to recursive retrieval, or recursion.
The maximum depth to which the retrieval may descend is specified with the ‘-l’ option. The default maximum depth is five layers.
By default, Wget will create a local directory tree, corresponding to the one found on the remote server.
Recursive retrieving can find a number of applications, the most important of which is mirroring. It is also useful for WWW presentations, and any other opportunities where slow network connections should be bypassed by storing the files locally.
You should be warned that recursive downloads can overload the remote servers. Because of that, many administrators frown upon them and may ban access from your site if they detect very fast downloads of big amounts of content. When downloading from Internet servers, consider using the ‘-w’ option to introduce a delay between accesses to the server. The download will take a while longer, but the server administrator will not be alarmed by your rudeness.
Recursive retrieval should be used with care. Don’t say you were not warned.
Leave a Reply
You must be logged in to post a comment.