
Os Detection Techniques and OS fingerprinting
Os Detection Techniques – Background information
This is a list of Os Detection Techniques, with explanations for all the active and passive Os Detection Techniques I can find for remote operating system identification – there is a massive list of sources at the end.
Background information: Os Detection Techniques
Active fingerprinting – Active fingerprinting is the process of transmitting packets to a remote host and analysing corresponding replies.
Passive fingerprinting – Passive fingerprinting is the process of analysing packets from a host on a network. In this case, finger printer acts as a sniffer and doesn’t put any traffic on a network.
Common Os Detection Techniques are based on analysing:
IP TTL values; IP ID values; TCP Window size; TCP Options (generally, in TCP SYN and SYN+ACK packets); DHCP requests; ICMP requests; HTTP packets (generally, User-Agent field). MDNS ARP / NDP / SEND DNLA UPNP – SSDP M-SEARCH Bonjour / Zeroconf NetBIOS SSH / SSL / TLS SDP SNMP
Other Os Detection Techniques are based on analysing:
Running services; Open port patterns. Limitations
Many passive fingerprinters are getting confused when analysing packets from a NAT device.
Os Detection Techniques – IP TTL values + TCP Window size
Certain parameters within the TCP protocol definition are left up to the implementation. Different operating systems, and different versions of the same operating system, set different defaults for these values. By collecting and examining these values, one may differentiate among various operating systems, and implementations of TCP/IP. The TCP/IP fields that may vary include the following:
Initial packet size (16 bits) Initial TTL (8 bits) Window size (16 bits) Max segment size (16 bits) Window scaling value (8 bits) “don’t fragment” flag (1 bit) “sackOK” flag (1 bit) “nop” flag (1 bit) These values may be combined to form a 67-bit signature, or fingerprint, for the target machine Just inspecting the Initial TTL and window size fields is often enough in order to successfully identify an operating system, which eases the task of performing manual OS fingerprinting.
Active measures, like those employed by Nmap, are unfortunately not available when doing passive analysis of live traffic or when analyzing previously captured network traffic. Passive analysis requires much more subtle variations in the network traffic to be observed, in order to identify a computer’s OS. A simple but effective passive method is to inspect the initial Time To Live (TTL) in the IP header and the TCP window size (the size of the receive window) of the first packet in a TCP session, i.e. the SYN or SYN+ACK packet.
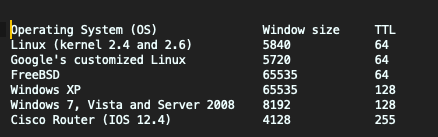
Below are some typical initial TTL values and window sizes of common operating systems:

IP ID values
TCP Options (generally, in TCP SYN and SYN+ACK packets);
Os Detection Techniques – DHCP requests
9.13. Vendor class identifier
This option is used by DHCP clients to optionally identify the vendor type and configuration of a DHCP client. The information is a string of n octets, interpreted by servers. Vendors may choose to define specific vendor class identifiers to convey particular configuration or other identification information about a client wich are useful OS Detection Techniques. For example, the identifier may encode the client’s hardware configuration. Servers not equipped to interpret the class-specific information sent by a client MUST ignore it (although it may be reported). Servers that the DHCP functionality supports the DHCP vendor class identifier option (option 60).
This support allows DHCP relay to compare option 60 strings in received DHCP client packets against strings that you configure on the router. You can use the DHCP relay option 60 feature when providing converged services in your network environment—option 60 support enables DHCP relay to direct client traffic to the specific DHCP server (the vendor-option server) that provides the service that the client requires. Or, as another option, you can configure option 60 strings to direct traffic to the DHCP local server in the current virtual router.
** you can also use this information to identify devices and operating systems
ICMP requests
Os Detection Techniques – ARP (Address Resolution Protocol)
The function or purpose of Internet Protocol is to move datagrams through an interconnected set of networks. This is done by passing the datagrams from one internet module to another until the destination is reached. The internet modules reside in hosts and gateways in the internet system. The datagrams are routed from one internet module to another through individual networks based on the interpretation of an internet address. Thus, one important mechanism of the internet protocol is the internet address.
By querying ARP you can get mac addressees, you can then use an OUI to look up manufacturer information, which can lead you to some other OS Detection Techniques.
Os Detection Techniques – Mac Addresses
A media access control address (MAC address) of a device is a unique identifier assigned to a network interface controller (NIC). For communications within a network segment, it is used as a network address for most IEEE 802 network technologies, including Ethernet, Wi-Fi, and Bluetooth. Within the Open Systems Interconnection (OSI) model, MAC addresses are used in the medium access control protocol sublayer of the data link layer. As typically represented, MAC addresses are recognisable as six groups of two hexadecimal digits, separated by hyphens, colons, or no separator (see Notational conventions below).
A MAC address may be referred to as the burned-in address, and is also known as an Ethernet hardware address, hardware address, and physical address (not to be confused with a memory physical address).
A network node with multiple NICs must have a unique MAC address for each. Sophisticated network equipment such as a multilayer switch or router may require one or more permanently assigned MAC addresses.
MAC addresses are most often assigned by the manufacturer of network interface cards. Each is stored in hardware, such as the card’s read-only memory or by a firmware mechanism. A MAC address typically includes the manufacturer’s organisationally unique identifier (OUI). MAC addresses are formed according to the principles of two numbering spaces based on Extended Unique Identifiers (EUI) managed by the Institute of Electrical and Electronics Engineers (IEEE): EUI-48, which replaces the obsolete term MAC-48,[1] and EUI-64.[2]
An organisationally unique identifier (OUI) is a 24-bit number that uniquely identifies a vendor, manufacturer, or other organisation.
OUIs are purchased from the Institute of Electrical and Electronics Engineers (IEEE) Registration Authority by the assignee (IEEE term for the vendor, manufacturer, or other organisation). They are used to uniquely identify a particular piece of equipment through derived identifiers such as MAC addresses, Subnetwork Access Protocol protocol identifiers, World Wide Names for Fibre Channel devices.
In MAC addresses, the OUI is combined with a 24-bit number (assigned by the assignee of the OUI) to form the address. The first three octets of the address are the OUI.
https://standards-oui.ieee.org/oui36/oui36.txt https://standards-oui.ieee.org/oui28/mam.txt https://standards-oui.ieee.org/oui/oui.txt https://standards-oui.ieee.org/iab/iab.txtThe Neighbour Discovery Protocol (NDP, ND) is a protocol in the Internet protocol suite used with Internet Protocol Version 6 (IPv6). It operates at the link layer of the Internet model (RFC 1122), and is responsible for gathering various information required for internet communication, including the configuration of local connections and the domain name servers and gateways used to communicate with more distant systems.[2]
Os Detection Techniques – NDP
The protocol defines five different ICMPv6 packet types to perform functions for IPv6 similar to the Address Resolution Protocol (ARP) and Internet Control Message Protocol (ICMP) Router Discovery and Router Redirect protocols for IPv4. However, it provides many improvements over its IPv4 counterparts (RFC 4861, section 3.1). For example, it includes Neighbour Unreachability Detection (NUD), thus improving robustness of packet delivery in the presence of failing routers or links, or mobile nodes.
The Inverse Neighbour Discovery (IND) protocol extension (RFC 3122) allows nodes to determine and advertise an IPv6 address corresponding to a given link-layer address, similar to Reverse ARP for IPv4. The Secure Neighbour Discovery Protocol (SEND), a security extension of NDP, uses Cryptographically Generated Addresses (CGA) and the Resource Public Key Infrastructure (RPKI) to provide an alternative mechanism for securing NDP with a cryptographic method that is independent of IPsec. Neighbour Discovery Proxy (ND Proxy) (RFC 4389) provides a service similar to IPv4 Proxy ARP and allows bridging multiple network segments within a single subnet prefix when bridging cannot be done at the link layer.
Os Detection Techniques – Bonjour / Zeroconf
Zero-configuration networking (zeroconf) is a set of technologies that automatically creates a usable computer network based on the Internet Protocol Suite (TCP/IP) when computers or network peripherals are interconnected. It does not require manual operator intervention or special configuration servers. Without zeroconf, a network administrator must set up network services, such as Dynamic Host Configuration Protocol (DHCP) and Domain Name System (DNS), or configure each computer’s network settings manually.
Zeroconf is built on three core technologies: automatic assignment of numeric network addresses for networked devices, automatic distribution and resolution of computer hostnames, and automatic location of network services, such as printing devices.
Service discovery Name services such as mDNS, LLMNR and others do not provide information about the type of device or its status. A user looking for a nearby printer, for instance, might be hindered if the printer was given the name “Bob”. Service discovery provides additional information about devices. Service discovery is sometimes combined with a name service, as in Apple’s Name Binding Protocol and Microsoft’s NetBIOS (including SMB as supported on non-Microsoft operating systems).
NetBIOS Service Discovery OS Detection Techniques – NetBIOS on Windows (and its sibling SMB on other operating systems) supports individual hosts on the network to advertise services, such as file shares and printers. It also supports for example a network printer to advertise itself as a host sharing a printer device and any related services it supports. Depending on how a device is attached (to the network directly, or to the host which shares it) and which protocols are supported however, Windows clients connecting to it may prefer to use SSDP or WSD over using NetBIOS. NetBIOS is one of the providers on Windows implementing the more general discovery process dubbed ‘Function Discovery’ which includes built-in providers for PnP, Registry, NetBIOS, SSDP and WSD of which the former two are local-only and the latter three support discovery of networked devices. None of these need any configuration for use on the local subnet. NetBIOS has traditionally been supported only in expensive printers for use in companies and the cheapest devices of some brands today still don’t have support for it, but home and SOHO users would connect printers to a computer over say a parallel port or USB and share it from the computer. However, today even entry-level printers with Wi-Fi or Ethernet support of some brands support it natively, allowing the printer to be used without configuration even on very old operating systems (combined with a generic PostScript driver, for example).
WS-Discovery – Web Services Dynamic Discovery (WS-Discovery) is a technical specification that defines a multicast discovery protocol to locate services on a local network. It operates over TCP andUDP port 3702 and uses IP multicast address 239.255.255.250. As the name suggests, the actual communication between nodes is done using web services standards, notably SOAP over UDP.Windows supports it in the form of WSD and WPDS and many device and appliance manufacturers support it, such as HP and Brother printers.
DNS-based OS Detection Techniques use service discovery DNS-SD allows clients to discover a named list of service instances, given a service type, and to resolve those services to hostnames using standard DNS queries. The specification is compatible with existing unicast DNS server and client software, but works equally well with mDNS in a zero-configuration environment. Each service instance is described using a DNS SRV ( RFC 2782) and DNS TXT (RFC 1035) record. A client discovers the list of available instances for a given service type by querying the DNS PTR (RFC 1035) record of that service type’s name; the server returns zero or more names of the form “.”, each corresponding to a SRV/TXT record pair. The SRV record resolves to the domain name providing the instance, while the TXT can contain service-specific configuration parameter. A client can then resolve the A/AAAA record for the domain name and connect to the service.
Apple Bonjour Bonjour (formerly known as Rendezvous) from Apple, uses mDNS and DNS Service Discovery. Apple changed its preferred zeroconf technology from SLP to mDNS and DNS-SD between Mac OS X 10.1 and 10.2, though SLP continues to be supported by Mac OS X.
Apple’s mDNSResponder has interfaces for C and Java[29] and is available on BSD, Apple Mac OS X, Linux, other POSIX based operating systems and MS Windows. The Windows downloads are available from Apple’s website.[30]
Os Detection Techniques – UPNP – SSDP M-SEARCH
Universal Plug and Play (UPnP) is a set of networking protocols that permits networked devices, such as personal computers, printers, Internet gateways, Wi-Fi access points and mobile devices to seamlessly discover each other’s presence on the network and establish functional network services for data sharing, communications, and entertainment. UPnP is intended primarily for residential networks without enterprise-class devices.
The UPnP technology was promoted by the UPnP Forum, a computer industry initiative to enable simple and robust connectivity to stand-alone devices and personal computers from many different vendors. The Forum consisted of over eight hundred vendors involved in everything from consumer electronics to network computing. Since 2016, all UPnP efforts are now managed by the Open Connectivity Foundation (OCF).[1]
UPnP assumes the network runs Internet Protocol (IP) and then leverages HTTP, on top of IP, in order to provide device/service description, actions, data transfer and eventing. Device search requests and advertisements are supported by running HTTP on top of UDP (port 1900) using multicast (known as HTTPMU). Responses to search requests are also sent over UDP, but are instead sent using unicast (known as HTTPU).
Conceptually, UPnP extends plug and play—a technology for dynamically attaching devices directly to a computer—to zero configuration networking for residential and SOHO wireless networks. UPnP devices are “plug and play” in that, when connected to a network, they automatically establish working configurations with other devices.
UPnP is generally regarded as unsuitable for deployment in business settings for reasons of economy, complexity, and consistency: the multicast foundation makes it chatty, consuming too many network resources on networks with a large population of devices; the simplified access controls don’t map well to complex environments; and it does not provide a uniform configuration syntax such as the CLI environments of Cisco IOS or JUNOS. UPnP leads to a number of different OS Detection Techniques.
The UPnP architecture allows device-to-device networking of consumer electronics, mobile devices, personal computers, and networked home appliances. It is a distributed, open architecture protocol based on established standards such as the Internet Protocol Suite (TCP/ IP), HTTP, XML, and SOAP. UPnP control points (CPs) are devices which use UPnP protocols to control UPnP controlled devices (CDs).[2]
The UPnP architecture supports zero configuration networking. A UPnP compatible device from any vendor can dynamically join a network, obtain an IP address, announce its name, advertise or convey its capabilities upon request, and learn about the presence and capabilities of other devices. Dynamic Host Configuration Protocol (DHCP) and Domain Name System (DNS) servers are optional and are only used if they are available on the network. Devices can disconnect from the network automatically without leaving state information.
OS Detection Techniques: Discovery
Once a device has established an IP address, the next step in UPnP networking is discovery. The UPnP discovery protocol is known as the Simple Service Discovery Protocol (SSDP). When a device is added to the network, SSDP allows that device to advertise its services to control points on the network. This is achieved by sending SSDP alive messages. When a control point is added to the network, SSDP allows that control point to actively search for devices of interest on the network or listen passively to the SSDP alive messages of device. The fundamental exchange is a discovery message containing a few essential specifics about the device or one of its services, for example, its type, identifier, and a pointer (network location) to more detailed information.
OS Detection Techniques: Description
After a control point has discovered a device, the control point still knows very little about the device. For the control point to learn more about the device and its capabilities, or to interact with the device, the control point must retrieve the device’s description from the location (URL) provided by the device in the discovery message. The UPnP Device Description is expressed in XML and includes vendor-specific manufacturer information like the model name and number, serial number, manufacturer name, (presentation) URLs to vendor-specific web sites, etc. The description also includes a list of any embedded services. For each service, the Device Description document lists the URLs for control, eventing and service description. Each service description includes a list of the commands, or actions, to which the service responds, and parameters, or arguments, for each action; the description for a service also includes a list of variables; these variables model the state of the service at run time, and are described in terms of their data type, range, and event characteristics.
Os Detection Techniques – SSDP
Simple Service Discovery Protocol (SSDP) is a UPnP protocol, used in Windows XP and later. SSDP uses HTTP notification announcements that give a service-type URI and a Unique Service Name (USN). Service types are regulated by the Universal Plug and Play Steering Committee. SSDP is supported by many printer, NAS and appliance manufacturers such as Brother, certain brands of network equipment, and in many SOHO firewall appliances, where host computers behind it may pierce holes for applications. It is also used in home theater PC systems, where media exchange between host computers and the media center is facilitated using SSDP.
Os Detection Techniques – MDNS
In computer networking, the multicast DNS (mDNS) protocol resolves host names to IP addresses within small networks that do not include a local name server. It is a zero-configuration service, using essentially the same programming interfaces, packet formats and operating semantics as the unicast Domain Name System (DNS). Although Stuart Cheshire designed mDNS as a stand-alone protocol, it can work in concert with standard DNS servers.[1]
The mDNS protocol is published as RFC 6762, uses IP multicast User Datagram Protocol (UDP) packets, and is implemented by the Apple Bonjour and open source Avahi software packages. Android contains an mDNS implementation. mDNS has also been implemented in Windows 10, but its use there is limited to discovering networked printers.
mDNS can work in conjunction with DNS Service Discovery (DNS-SD), a companion zero-configuration technique specified separately in RFC 6763.
Os Detection Techniques – DNLA
Digital Living Network Alliance (DLNA) (originally named Digital Home Working Group, DHWG) was founded by a group of PC and consumer electronics companies in June 2003 (with Intel in the lead role) to develop and promote a set of interoperability guidelines for sharing digital media among multimedia devices under the auspice of a certification standard. DLNA certified devices include smartphones, tablets, PCs, TV sets and storage servers; in a typical use case, a user sends videos, pictures or music from their smartphone or storage server through their home WLAN to a TV set or tablet for display.
The DLNA Certified Device Classes are separated as follows:[10]
Home Network Devices
Digital Media Server (DMS): store content and make it available to networked digital media players (DMP) and digital media renderers (DMR). Examples include PCs and network-attached storage (NAS) devices.
Digital Media Player (DMP): find content on digital media servers (DMS) and provide playback and rendering capabilities. Examples include TVs, stereos and home theaters, wireless monitors and game consoles.
Digital Media Renderer (DMR): play content as instructed by a digital media controller (DMC), which will find content from a digital media server (DMS). Examples include TVs, audio/video receivers, video displays and remote speakers for music. It is possible for a single device (e.g. TV, A/V receiver, etc.) to function both as a DMR (receives “pushed” content from DMS) and DMP (“pulls” content from DMS)
Digital Media Controller (DMC): find content on digital media servers (DMS) and instruct digital media renderers (DMR) to play the content. Content doesn’t stream from or through the DMC. Examples include tablet computers, Wi-Fi enabled digital cameras and smartphones. Generally, digital media players (DMP) and digital media controllers (DMC) with print capability can print to DMPr. Examples include networked photo printers and networked all-in-one printers
Mobile Digital Media Server (M-DMS): store content and make it available to wired/wireless networked mobile digital media players (M-DMP), and digital media renderers. Examples include mobile phones and portable music players.
Mobile Digital Media Player (M-DMP): find and play content on a digital media server (DMS) or mobile digital media server (M-DMS). Examples include mobile phones and mobile media tablets designed for viewing multimedia content.
Mobile Digital Media Uploader (M-DMU): send (upload) content to a digital media server (DMS) or mobile digital media server (M-DMS). Examples include digital cameras and mobile phones.
Mobile Digital Media Downloader (M-DMD): find and store (download) content from a digital media server (DMS) or mobile digital media server (M-DMS). Examples include portable music players and mobile phones.
Mobile Digital Media Controller (M-DMC): find content on a digital media server (DMS) or mobile digital media server (M-DMS) and send it to digital media renderers (DMR). Examples include personal digital assistants (PDAs) and mobile phones.
Mobile Network Connectivity Function (M-NCF): provide a bridge between mobile handheld device network connectivity and home network connectivity.
Media Interoperability Unit (MIU): provide content transformation between required media formats for home network and mobile handheld devices.
The specification uses DTCP-IP as “link protection” for copyright-protected commercial content between one device to another.
DLNA is another suite of standards that uses UPnP for its discovery of networked devices, which has a long list of manufacturers producing devices that support it, such as TVs from most if not all large brands, NAS devices and so forth. As such, it is also supported by all major operating systems.
DNLA leads to a number of OS Detection Techniques as devices tend to identify their capabilities on the network when queried.
Os Detection Techniques – NetBIOS / SMB / NTLM
NetBIOS over TCP/IP (NBT, or sometimes NetBT) is a networking protocol that allows legacy computer applications relying on the NetBIOS API to be used on modern TCP/IP networks.
NetBIOS was developed in the early 1980s, targeting very small networks (about a dozen computers). Some applications still use NetBIOS, and do not scale well in today’s networks of hundreds of computers when NetBIOS is run over NBF. When properly configured, NBT allows those applications to be run on large TCP/IP networks (including the whole Internet, although that is likely to be subject to security problems) without change.
NBT is defined by the RFC 1001 and RFC 1002 standard documents.
NetBIOS provides three distinct OS Detection Techniques / services:
Name service for name registration and resolution (ports: 137/udp and 137/tcp) Datagram distribution service for connectionless communication (port: 138/udp) Session service for connection-oriented communication (port: 139/tcp) NBT implements all of those services.
Although its main purpose is file sharing, additional SMB Protocol provides other functionality such as:
Network browsing Printing over a network SMB Protocol is most often used as an Application layer or a Presentation layer protocol, and it relies on lower-level protocols for transport.
The transport layer protocol that Microsoft SMB Protocol was often used with was NetBIOS over TCP/IP (NBT) over UDP ports 137 and 138 and TCP ports 137 and 139. NBT for use by NetBIOS is supported on Windows Server 2003, Windows XP, Windows 2000, Windows NT, and Windows Me/98/95. NetBIOS is not supported on Windows Vista, Windows Server 2008, and subsequent versions of Windows. SMB/NBT combination is generally used for backward compatibility. The NetBIOS over NetBEUI protocol provides NetBIOS support for the NetBEUI protocol. This protocol is also called NetBIOS Frames (NBF). NBF is supported on Windows 2000, Windows NT, and Windows Me/98/95. NetBEUI is no longer be supported on Windows XP and later. However, SMB Protocol can also be used without a separate transport protocol directly over TCP, port 445. NetBIOS was also supported over several legacy protocols such as IPX/SPX. The SMB “Inter-Process Communication” (IPC) system provides named pipes and was one of the first inter-process mechanisms commonly available to programmers that provides a means for services to inherit the authentication carried out when a client[clarification needed] first connects to an SMB server.[citation needed]
Some services that operate over named pipes, such as those which use Microsoft’s own implementation of DCE/RPC over SMB, known as MSRPC over SMB, also allow MSRPC client programs to perform authentication, which overrides the authorization provided by the SMB server, but only in the context of the MSRPC client program that successfully makes the additional authentication.
SMB signing: Windows NT 4.0 Service Pack 3 and upwards have the capability to use cryptography to digitally sign SMB connections. The most common official term is “SMB signing”. Other terms that have been used officially are “[SMB] Security Signatures”, “SMB sequence numbers”[5] and “SMB Message Signing”.[6] SMB signing may be configured individually for incoming SMB connections (handled by the “LanManServer” service) and outgoing SMB connections (handled by the “LanManWorkstation” service). The default setting from Windows 98 and upwards is to opportunistically sign outgoing connections whenever the server also supports this, and to fall back to unsigned SMB if both partners allow this. The default setting for Windows domain controllers from Windows Server 2003 and upwards is to not allow fall back for incoming connections.[7] The feature can also be turned on for any server running Windows NT 4.0 Service Pack 3 or later. This protects from man-in-the-middle attacks against the Clients retrieving their policies from domain controllers at login.[8]
The design of Server Message Block version 2 (SMB2) aims[citation needed] to mitigate this performance limitation by coalescing SMB signals into single packets.
SMB supports opportunistic locking—a special type of locking-mechanism—on files in order to improve performance.
SMB serves as the basis for Microsoft’s Distributed File System implementation.
Os Detection Techniques – SDP
Protocols There are many service discovery protocols, including:
Bluetooth Service Discovery Protocol (SDP) DNS Service Discovery (DNS-SD), a component of Zero Configuration Networking Dynamic Host Configuration Protocol (DHCP) Internet Storage Name Service (iSNS) Jini for Java objects. Link-Layer Discovery Protocol (LLDP) standards-based neighbor discovery protocol similar to vendor-specific protocols which find each other by advertising to vendor-specific broadcast addresses (versus all-1’s), such Cabletron (Enterasys) and Cisco Discovery Protocol (both referred to as CDP but different formats). Multicast Source Discovery Protocol (MSDP), usually used for unicast exchange of multicast source information between anycast Rendez-Vous Points (RPs) to service mcast clients. Service Location Protocol (SLP) Session Announcement Protocol (SAP) used to discover RTP sessions Simple Service Discovery Protocol (SSDP) a component of Universal Plug and Play (UPnP) Universal Description Discovery and Integration (UDDI) for web services Web Proxy Autodiscovery Protocol (WPAD) WS-Discovery (Web Services Dynamic Discovery) XMPP Service Discovery (XEP-0030) XRDS (eXtensible Resource Descriptor Sequence) used by XRI, OpenID, OAuth, etc.While not specific for OS Detection Techniques bluetooth can be used to identify devices and can be combined with other OS Detection Techniques to identify devices.
Efforts toward an IETF standard protocol Service Location Protocol (SLP) is supported by Hewlett-Packard’s network printers, Novell, and Sun Microsystems. SLP is described in RFC 2608 and RFC 3224 and implementations are available for both Solaris and Linux.
AllJoyn AllJoyn is an open source software stack for a myriad of devices, ranging from the tiniest IoT devices to the largest computers, for discovery and control of devices on networks (Wifi, Ethernet) and other links (Bluetooth, ZigBee, etc.). It uses (amongst others) mDNS and HTTP over UDP.
Os Detection Techniques – SNMP
Simple Network Management Protocol (SNMP) is an Internet Standard protocol for collecting and organizing information about managed devices on IP networks and for modifying that information to change device behavior. Devices that typically support SNMP include cable modems, routers, switches, servers, workstations, printers, and more.[1] This makes the protocol available for various OS Detection Techniques.
SNMP is widely used in network management for network monitoring. SNMP exposes management data in the form of variables on the managed systems organized in a management information base ( MIB) which describe the system status and configuration. These variables can then be remotely queried (and, in some circumstances, manipulated) by managing applications.
Many SNMP implementations include a type of automatic discovery where a new network component, such as a switch or router, is discovered and pooled automatically. In SNMPv1 and v2c this is done through a community string that is broadcast in clear-text to other devices.[10] Because of its default configuration on community strings, they are public for read-only access and private for read-write[8]:1874 SNMP topped the list of the SANS Institute’s Common Default Configuration Issues and was number ten on the SANS Top 10 Most Critical Internet Security Threats for the year 2000.[28] System and network administrators frequently do not change these configurations.[8]:1874 The community string sent by SNMP over the network is not encrypted. Once the community string is known outside the organisation it could become the target for an attack. To prevent the easy discovery of the community, SNMP should be configured to pass community-name authentication failure traps and the SNMP management device needs to be configured to react to the authentication failure trap.[25]:54
SSH / SSL / TLS Os Detection Techniques
SSH fingerprinting Hash is a new SSH Fingerprinting standard used to accurately detect and identify specific Client and Server SSH deployments. These fingerprints uses MD5 as a default storage method, for later analysis, usage and comparison when needed. These methods can be used for Os Detection Techniques.
While SSH is a fairly secure protocol, it has a few drawbacks when it comes to analyzing interaction between client and server. In this case, using Hassh can help in situations that include:
Managing alerts and automatically blocking SSH clients using a Hassh fingerprint outside of a known “good set”. Detecting exfiltration of data by using anomaly detection on SSH Clients with multiple distinct Hassh values. Forensic investigation as SSH connection attempts are now easier to find, with greater granularity than researching by IPSource. The Hassh will be present within SSH client software, this will help to detect the origin even if the IP is behind a NAT and is shared by different SSH clients. Detecting and identifying specific client and server SSH implementations. This works by using the MD5 “hassh” and “hasshServer” (created from a specific set of algorithms by SSH clients and SSH server software) from the final SSH encrypted channel. This generates a unique identification string that can be used to fingerprint client and server applications.
The final MD5 can be easily translated into examples such as these:
c1c596caaeb93c566b8ecf3cae9b5a9e SSH-2.0-dropbear_2016.74 d93f46d063c4382b6232a4d77db532b2 SSH-2.0-dropbear_2016.72 2dd9a9b3dbebfaeec8b8aabd689e75d2 SSH-2.0-AWSCodeCommit Hassh is a brand new project, online since their Github repo a few months ago.id It looks like a solid solution, one that can shed light on the typical SSH client-server connection problems seen for decades. Thanks to this new fingerprint standart, debugging SSH connections will be easier.
SSL fingerprinting JA3, as their creators said, is an SSL/TLS fingerprint method. This helps to create fingerprints that can be produced by any platform for later threat intelligence analysis.
In the same case as the previous technology (HASSH), using JA3 + JA3S as a fingerprinting technique for the TLS negotiation between both ends (client and server) can produce a more accurate identification of the encrypted communications.
This helps identify clients and servers with high probability in almost all cases, as you see below with Tor client and Tor server:
Standard Tor Client:
JA3 = e7d705a3286e19ea42f587b344ee6865 (Tor Client) JA3S = a95ca7eab4d47d051a5cd4fb7b6005dc (Tor Server Response) This provides researchers a higher level of trust that this activity is indeed Tor traffic, and nothing else.
More information can be found at https://github.com/salesforce/ja3/
HTTP packets (generally, User-Agent field).
Os Detection Techniques using HTTP. In computing, a user agent is software (a software agent) that is acting on behalf of a user. One common use of the term refers to a web browser that “retrieves, renders and facilitates end user interaction with Web content”.[1] There are other uses of the term “user agent”. For example, an email reader is a mail user agent. In many cases, a user agent acts as a client in a network protocol used in communications within a client–server distributed computing system. In particular, the Hypertext Transfer Protocol (HTTP) identifies the client software originating the request, using a user-agent header, even when the client is not operated by a user. The Session Initiation Protocol (SIP) protocol (based on HTTP) followed this usage. In the SIP, the term user agent refers to both end points of a communications session.[2]
In HTTP, the User-Agent string is often used for content negotiation, where the origin server selects suitable content or operating parameters for the response. For example, the User-Agent string might be used by a web server to choose variants based on the known capabilities of a particular version of client software. The concept of content tailoring is built into the HTTP standard in RFC 1945 “for the sake of tailoring responses to avoid particular user agent limitations.”
OS Detection Techniques using the User-Agent string. The User-Agent is one of the criteria by which Web crawlers may be excluded from accessing certain parts of a website using the Robots Exclusion Standard (robots.txt file).
As with many other HTTP request headers, the information in the “User-Agent” string contributes to the information that the client sends to the server, since the string can vary considerably from user to user.[5]
Format for human-operated web browsers The User-Agent string format is currently specified by section 5.5.3 of HTTP/1.1 Semantics and Content. The format of the User-Agent string in HTTP is a list of product tokens (keywords) with optional comments. For example, if a user’s product were called WikiBrowser, their user agent string might be WikiBrowser/1.0 Gecko/1.0. The “most important” product component is listed first.
The parts of this string are as follows:
product name and version (WikiBrowser/1.0) layout engine and version (Gecko/1.0) During the first browser war, many web servers were configured to only send web pages that required advanced features, including frames, to clients that were identified as some version of Mozilla.[6] Other browsers were considered to be older products such as Mosaic, Cello, or Samba, and would be sent a bare bones HTML document.
For this reason, most Web browsers use a User-Agent string value as follows:
Mozilla/[version] ([system and browser information]) [platform] ([platform details]) [ extensions]. For example, Safari on the iPad has used the following:
Mozilla/5.0 (iPad; U; CPU OS 3_2_1 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Mobile/7B405 The components of this string are as follows:
Mozilla/5.0: Previously used to indicate compatibility with the Mozilla rendering engine. (iPad; U; CPU OS 3_2_1 like Mac OS X; en-us): Details of the system in which the browser is running. AppleWebKit/531.21.10: The platform the browser uses. (KHTML, like Gecko): Browser platform details.
Mobile/7B405: This is used by the browser to indicate specific enhancements that are available directly in the browser or through third parties. An example of this is Microsoft Live Meeting which registers an extension so that the Live Meeting service knows if the software is already installed, which means it can provide a streamlined experience to joining meetings. Before migrating to the Chromium code base, Opera was the most widely used web browser that did not have the User-Agent string with “Mozilla” (instead beginning it with “Opera”).
Since July 15, 2013,[7] Opera’s User-Agent string begins with “Mozilla/5.0” and, to avoid encountering legacy server rules, no longer includes the word “Opera” (instead using the string “OPR” to denote the Opera version).
OS Detection Techniques – User-Agent Sniffing
The term user agent sniffing refers to the practice of websites showing different content when viewed with a certain user agent. On the Internet, this will result in a different site being shown when browsing the page with a specific browser. One example of this is Microsoft Exchange Server 2003’s Outlook Web Access feature. When viewed with Internet Explorer 6 or newer, more functionality is displayed compared to the same page in any other browsers. User agent sniffing is now considered poor practice, since it encourages browser-specific design and penalizes new browsers with unrecognized user agent identifications. Instead, the W3C recommends creating HTML markup that is standard,[11] allowing correct rendering in as many browsers as possible, and to test for specific browser features rather than particular browser versions or brands.[12]
Websites specifically targeted towards mobile phones, like NTT DoCoMo’s I-Mode or Vodafone’s Vodafone Live! portals, often rely heavily on user agent sniffing, since mobile browsers often differ greatly from each other. Many developments in mobile browsing have been made in the last few years,[when?] while many older phones that do not possess these new technologies are still heavily used. Therefore, mobile Web portals will often generate completely different markup code depending on the mobile phone used to browse them. These differences can be small, e.g., resizing of certain images to fit smaller screens, or quite extensive, e.g., rendering of the page in WML instead of XHTML.
Common Platform Enumeration (CPE)
https://nvd.nist.gov/products/cpe
Common Platform Enumeration (CPE) is a standardized way to name software applications, operating systems, and hardware platforms. As such, it is perfect for OS Detection Techniques – Nmap includes CPE output for service and Os Detection Techniques.
Structure of a CPE Name – A CPE name is a URL that encodes seven ordered fields:
cpe:/::::::
Some of the fields may be left blank, and empty fields may be left off the end of the URL. The main division of CPE names is in the field; this can take on only three values:
a for applications, h for hardware platforms, or o for operating systems. By looking at the beginning of the URL you can easily see that cpe:/a:microsoft:sql_server:6.5 names an application, cpe:/h:asus:rt-n16 names a kind of hardware, and cpe:/o:freebsd:freebsd:3.5.1 names an operating system.
Nmap can output all three kinds of CPE names: OS detection can print h and o; and service detection can potentially output all three. The CPE names are mixed in with normal OS and service output, for example:
Example 13.13. Normal output with CPE highlighted
Running: Linux 2.6.X OS CPE: cpe:/o:linux:linux_kernel:2.6.39 OS details: Linux 2.6.39 Network Distance: 10 hops Service Info: OS: Linux; CPE: cpe:/o:linux:kernel
CPE names for applications (with part a) are not shown in normal output, but they are present in XML. CPE is represented as a cpe element that can be a child of service or osclass.
Standard Discovery Protocol
Efforts toward an IETF standard protocol Service Location Protocol (SLP) is supported by Hewlett-Packard’s network printers, Novell, and Sun Microsystems. SLP is described in RFC 2608 and RFC 3224 and implementations are available for both Solaris and Linux.
Tools
Os Detection Techniques – Active fingerprinters
Nmap
Os Detection Techniques – Passive fingerprinters
NetworkMiner
p0f
Satori
Os Detection Techniques – Others:
Scapy
check out these linux commands
A list of TCP/OS Fingerprinting Tools
Ettercap – passive TCP/IP stack fingerprinting.
NetworkMiner – passive DHCP and TCP/IP stack fingerprinting (combines p0f, Ettercap and Satori databases)
Nmap – comprehensive active stack fingerprinting.
p0f – comprehensive passive TCP/IP stack fingerprinting.
NetSleuth – free passive fingerprinting and analysis tool
PacketFence[8] – open source NAC with passive DHCP fingerprinting.
PRADS – Passive comprehensive TCP/IP stack fingerprinting and service detection
Satori – passive CDP, DHCP, ICMP, HPSP, HTTP, TCP/IP and other stack fingerprinting.
SinFP – single-port active/passive fingerprinting.
XProbe2 – active TCP/IP stack fingerprinting.
Device Fingerprint Website[9] – Displays the passive TCP SYN fingerprint of your browser’s computer (or intermediate proxy)
queso – well-known tool from the late 1990s which is no longer being updated for modern operating systems
fpdns
Hassh
check out these linux commands
TCP/IP Fingerprinting Methods Supported by Nmap – Os Detection Techniques
Nmap Os Detection Techniques employ fingerprinting which works by sending up to 16 TCP, UDP, and ICMP probes to known open and closed ports of the target machine. These probes are specially designed to exploit various ambiguities in the standard protocol RFCs. Then Nmap listens for responses. Dozens of attributes in those responses are analyzed and combined to generate a fingerprint. Every probe packet is tracked and resent at least once if there is no response. All of the packets are IPv4 with a random IP ID value. Probes to an open TCP port are skipped if no such port has been found. For closed TCP or UDP ports, Nmap will first check if such a port has been found. If not, Nmap will just pick a port at random and hope for the best.
closed ports of the target machine. These probes are specially designed to exploit various ambiguities in the standard protocol RFCs. Then Nmap listens for responses. Dozens of attributes in those responses are analyzed and combined to generate a fingerprint. Every probe packet is tracked and resent at least once if there is no response. All of the packets are IPv4 with a random IP ID value. Probes to an open TCP port are skipped if no such port has been found. For closed TCP or UDP ports, Nmap will first check if such a port has been found. If not, Nmap will just pick a port at random and hope for the best.
The following sections are highly technical and reveal the hidden workings of Nmap Os Detection Techniques. Nmap can be used effectively without understanding this, though the material can help you better understand remote networks and also detect and explain certain anomalies. Plus, some of the Os Detection Techniques are pretty cool. Readers in a hurry may skip to the section called “Dealing with Misidentified and Unidentified Hosts”. But for those of you who are ready for a journey through TCP explicit congestion notification, reserved UDP header bits, initial sequence numbers, bogus flags, and Christmas tree packets: read on!
Even the best of us occasionally forget byte offsets for packet header fields and flags. For quick reference, the IPv4, TCP, UDP, and ICMP header layouts can be found in the section called “TCP/IP Reference”. The layout for ICMP echo request and destination unreachable packets are shown in Figure 8.1 and Figure 8.2.
**Figure 8.1. ICMP echo request or reply header layout
ICMP echo request or reply header layout
**Figure 8.2. ICMP destination unreachable header layout
ICMP destination unreachable header layout
Probes Sent This section describes each IP probe sent by Nmap as part of TCP/IP fingerprinting. It refers to Nmap response tests and TCP options which are explained in the following section.
Sequence generation (SEQ, OPS, WIN, and T1) A series of six TCP probes is sent to generate these four test response lines. The probes are sent exactly 100 milliseconds apart so the total time taken is 500 ms. Exact timing is important as some of the sequence algorithms we detect (initial sequence numbers, IP IDs, and TCP timestamps) are time dependent. This timing value was chosen to take 500 ms so that we can reliably detect the common 2 Hz TCP timestamp sequences.
Each probe is a TCP SYN packet to a detected open port on the remote machine. The sequence and acknowledgment numbers are random (but saved so Nmap can differentiate responses). Detection accuracy requires probe consistency, so there is no data payload even if the user requested one with –data-length.
These packets vary in the TCP options they use and the TCP window field value. The following list provides the options and values for all six packets. The listed window field values do not reflect window scaling. EOL is the end-of-options-list option, which many sniffing tools don’t show by default.
Packet #1: window scale (10), NOP, MSS (1460), timestamp (TSval: 0xFFFFFFFF; TSecr: 0), SACK permitted. The window field is 1.
Packet #2: MSS (1400), window scale (0), SACK permitted, timestamp (TSval: 0xFFFFFFFF; TSecr: 0), EOL. The window field is 63.
Packet #3: Timestamp (TSval: 0xFFFFFFFF; TSecr: 0), NOP, NOP, window scale (5), NOP, MSS (640). The window field is 4.
Packet #4: SACK permitted, Timestamp (TSval: 0xFFFFFFFF; TSecr: 0), window scale (10), EOL. The window field is 4.
Packet #5: MSS (536), SACK permitted, Timestamp (TSval: 0xFFFFFFFF; TSecr: 0), window scale (10), EOL. The window field is 16.
Packet #6: MSS (265), SACK permitted, Timestamp (TSval: 0xFFFFFFFF; TSecr: 0). The window field is 512.
The results of these tests include four result category lines. The first, SEQ, contains results based on sequence analysis of the probe packets. These test results are GCD, SP, ISR, TI, II, TS, and SS. The next line, OPS contains the TCP options received for each of the probes (the test names are O1 through 06). Similarly, the WIN line contains window sizes for the probe responses (named W1 through W6). The final line related to these probes, T1, contains various test values for packet #1. Those results are for the R, DF, T, TG, W, S, A, F, O, RD, and Q tests. These tests are only reported for the first probe since they are almost always the same for each probe.
ICMP echo (IE) The IE test involves sending two ICMP echo request packets to the target. The first one has the IP DF bit set, a type-of-service (TOS) byte value of zero, a code of nine (even though it should be zero), the sequence number 295, a random IP ID and ICMP request identifier, and 120 bytes of 0x00 for the data payload.
The second ping query is similar, except a TOS of four (IP_TOS_RELIABILITY) is used, the code is zero, 150 bytes of data is sent, and the ICMP request ID and sequence numbers are incremented by one from the previous query values.
The results of both of these probes are combined into a IE line containing the R, DFI, T, TG, and CD tests. The R value is only true (Y) if both probes elicit responses. The T, and CD values are for the response to the first probe only, since they are highly unlikely to differ. DFI is a custom test for this special dual-probe ICMP case.
These ICMP probes follow immediately after the TCP sequence probes to ensure valid results of the shared IP ID sequence number test (see the section called “Shared IP ID sequence Boolean (SS)”).
TCP explicit congestion notification (ECN) This probe tests for explicit congestion notification (ECN) support in the target TCP stack. ECN is a method for improving Internet performance by allowing routers to signal congestion problems before they start having to drop packets. It is documented in RFC 3168. Nmap tests this by sending a SYN packet which also has the ECN CWR and ECE congestion control flags set. For an unrelated (to ECN) test, the urgent field value of 0xF7F5 is used even though the urgent flag is not set. The acknowledgment number is zero, sequence number is random, window size field is three, and the reserved bit which immediately precedes the CWR bit is set. TCP options are WScale (10), NOP, MSS (1460), SACK permitted, NOP, NOP. The probe is sent to an open port.
If a response is received, the R, DF, T, TG, W, O, CC, and Q tests are performed and recorded.
TCP (T2–T7) The six T2 through T7 tests each send one TCP probe packet. With one exception, the TCP options data in each case is (in hex) 03030A0102040109080AFFFFFFFF000000000402. Those 20 bytes correspond to window scale (10), NOP, MSS (265), Timestamp (TSval: 0xFFFFFFFF; TSecr: 0), then SACK permitted. The exception is that T7 uses a Window scale value of 15 rather than 10. The variable characteristics of each probe are described below:
T2 sends a TCP null (no flags set) packet with the IP DF bit set and a window field of 128 to an open port.
T3 sends a TCP packet with the SYN, FIN, URG, and PSH flags set and a window field of 256 to an open port. The IP DF bit is not set.
T4 sends a TCP ACK packet with IP DF and a window field of 1024 to an open port.
T5 sends a TCP SYN packet without IP DF and a window field of 31337 to a closed port.
T6 sends a TCP ACK packet with IP DF and a window field of 32768 to a closed port.
T7 sends a TCP packet with the FIN, PSH, and URG flags set and a window field of 65535 to a closed port. The IP DF bit is not set.
In each of these cases, a line is added to the fingerprint with results for the R, DF, T, TG, W, S, A, F, O, RD, and Q tests.
UDP (U1) This probe is a UDP packet sent to a closed port. The character ‘C’ (0x43) is repeated 300 times for the data field. The IP ID value is set to 0x1042 for operating systems which allow us to set this. If the port is truly closed and there is no firewall in place, Nmap expects to receive an ICMP port unreachable message in return. That response is then subjected to the R, DF, T, TG, IPL, UN, RIPL, RID, RIPCK, RUCK, and RUD tests.
Response Tests The previous section describes probes sent by Nmap, and this one completes the puzzle by describing the barrage of tests performed on responses. The short names (such as DF, R, and RIPCK) are those used in the nmap-os-db fingerprint database to save space. All numerical test values are given in hexadecimal notation, without leading zeros, unless noted otherwise. The tests are documented in roughly the order they appear in fingerprints.
TCP ISN greatest common divisor (GCD) The SEQ test sends six TCP SYN packets to an open port of the target machine and collects SYN/ ACK packets back. Each of these SYN/ACK packets contains a 32-bit initial sequence number ( ISN). This test attempts to determine the smallest number by which the target host increments these values. For example, many hosts (especially old ones) always increment the ISN in multiples of 64,000.
The first step in calculating this is creating an array of differences between probe responses. The first element is the difference between the 1st and 2nd probe response ISNs. The second element is the difference between the 2nd and 3rd responses. There are five elements if Nmap receives responses to all six probes. Since the next couple of sections reference this array, we will call it diff1. If an ISN is lower than the previous one, Nmap looks at both the number of values it would have to subtract from the first value to obtain the second, and the number of values it would have to count up (including wrapping the 32-bit counter back to zero). The smaller of those two values is stored in diff1. So the difference between 0x20000 followed by 0x15000 is 0xB000. The difference between 0xFFFFFF00 and 0xC000 is 0xC0FF. This test value then records the greatest common divisor of all those elements. This GCD is also used for calculating the SP result.
TCP ISN counter rate (ISR) This value reports the average rate of increase for the returned TCP initial sequence number. Recall that a difference is taken between each two consecutive probe responses and stored in the previously discussed diff1 array. Those differences are each divided by the amount of time elapsed (in seconds—will generally be about 0.1) between sending the two probes which generated them. The result is an array, which we’ll call seq_rates containing the rates of ISN counter increases per second. The array has one element for each diff1 value. An average is taken of the array values. If that average is less than one (e.g. a constant ISN is used), ISR is zero. Otherwise ISR is eight times the binary logarithm (log base-2) of that average value, rounded to the nearest integer.
TCP ISN sequence predictability index (SP) While the ISR test measures the average rate of initial sequence number increments, this value measures the ISN variability. It roughly estimates how difficult it would be to predict the next ISN from the known sequence of six probe responses. The calculation uses the difference array (seq_rates) and GCD values discussed in the previous section.
This test is only performed if at least four responses were seen. If the previously computed GCD value is greater than nine, the elements of the previously computed seq_rates array are divided by that value. We don’t do the division for smaller GCD values because those are usually caused by chance. A standard deviation of the array of the resultant values is then taken. If the result is one or less, SP is zero. Otherwise the binary logarithm of the result is computed, then it is multiplied by eight, rounded to the nearest integer, and stored as SP.
Please keep in mind that this test is only done for Os Detection Techniques and is not a full-blown audit of the target ISN generator. There are many algorithm weaknesses that lead to easy predictability even with a high SP value.
IP ID sequence generation algorithm (TI, CI, II) There are three tests that examine the IP header ID field of responses. TI is based on responses to the TCP SEQ probes. CI is from the responses to the three TCP probes sent to a closed port: T5, T6, and T7. II comes from the ICMP responses to the two IE ping probes. For TI, at least three responses must be received for the test to be included; for CI, at least two responses are required; and for II, both ICMP responses must be received.
For each of these tests, the target’s IP ID generation algorithm is classified based on the algorithm below. Minor differences between tests are noted. Note that difference values assume that the counter can wrap. So the difference between an IP ID of 65,100 followed by a value of 700 is 1,136. The difference between 2,000 followed by 1,100 is 64,636. Here are the calculation details:
If all of the ID numbers are zero, the value of the test is Z.
If the IP ID sequence ever increases by at least 20,000, the value is RD (random). This result isn’t possible for II because there are not enough samples to support it.
If all of the IP IDs are identical, the test is set to that value in hex.
If any of the differences between two consecutive IDs exceeds 1,000, and is not evenly divisible by 256, the test’s value is RI (random positive increments). If the difference is evenly divisible by 256, it must be at least 256,000 to cause this RI result.
If all of the differences are divisible by 256 and no greater than 5,120, the test is set to BI (broken increment). This happens on systems like Microsoft Windows where the IP ID is sent in host byte order rather than network byte order. It works fine and isn’t any sort of RFC violation, though it does give away host architecture details which can be useful to attackers.
If all of the differences are less than ten, the value is I (incremental). We allow difference up to ten here (rather than requiring sequential ordering) because traffic from other hosts can cause sequence gaps.
If none of the previous steps identify the generation algorithm, the test is omitted from the fingerprint.
Shared IP ID sequence Boolean (SS) This Boolean value records whether the target shares its IP ID sequence between the TCP and ICMP protocols. If our six TCP IP ID values are 117, 118, 119, 120, 121, and 122, then our ICMP results are 123 and 124, it is clear that not only are both sequences incremental, but they are both part of the same sequence. If, on the other hand, the TCP IP ID values are 117–122 but the ICMP values are 32,917 and 32,918, two different sequences are being used.
This test is only included if II is RI, BI, or I and TI is the same. If SS is included, the result is S if the sequence is shared and O (other) if it is not. That determination is made by the following algorithm:
Let avg be the final TCP sequence response IP ID minus the first TCP sequence response IP ID, divided by the difference in probe numbers. If probe #1 returns an IP ID of 10,000 and probe #6 returns 20,000, avg would be (20,000 − 10,000) / (6 − 1), which equals 2,000.
If the first ICMP echo response IP ID is less than the final TCP sequence response IP ID plus three times avg, the SS result is S. Otherwise it is O.
TCP timestamp option algorithm (TS) TS is another test which attempts to determine target OS characteristics based on how it generates a series of numbers. This one looks at the TCP timestamp option (if any) in responses to the SEQ probes. It examines the TSval (first four bytes of the option) rather than the echoed TSecr (last four bytes) value. It takes the difference between each consecutive TSval and divides that by the amount of time elapsed between Nmap sending the two probes which generated those responses. The resultant value gives a rate of timestamp increments per second. Nmap computes the average increments per second over all consecutive probes and then calculates the TS as follows:
If any of the responses have no timestamp option, TS is set to U (unsupported).
If any of the timestamp values are zero, TS is set to 0.
If the average increments per second falls within the ranges 0-5.66, 70-150, or 150-350, TS is set to 1, 7, or 8, respectively. These three ranges get special treatment because they correspond to the 2 Hz, 100 Hz, and 200 Hz frequencies used by many hosts.
In all other cases, Nmap records the binary logarithm of the average increments per second, rounded to the nearest integer. Since most hosts use 1,000 Hz frequencies, A is a common result.
TCP options (O, O1–O6) This test records the TCP header options in a packet. It preserves the original ordering and also provides some information about option values. Because RFC 793 doesn’t require any particular ordering, implementations often come up with unique orderings. Some platforms don’t implement all options (they are, of course, optional). When you combine all of those permutations with the number of different option values that implementations use, this test provides a veritable trove of information. The value for this test is a string of characters representing the options being used. Several options take arguments that come immediately after the character. Supported options and arguments are all shown in Table 8.1.
Table 8.1. O test values
Option Name Character Argument (if any) End of Options List (EOL) L No operation (NOP) N Maximum Segment Size (MSS) M The value is appended. Many systems echo the value used in the corresponding probe. Window Scale (WS) W The actual value is appended. Timestamp (TS) T The T is followed by two binary characters representing the TSval and TSecr values respectively. The characters are 0 if the field is zero and 1 otherwise. Selective ACK permitted (SACK) S
As an example, the string M5B4NW3NNT11 means the packet includes the MSS option (value 0x5B4) followed by a NOP. Next comes a window scale option with a value of three, then two more NOPs. The final option is a timestamp, and neither of its two fields were zero. If there are no TCP options in a response, the test will exist but the value string will be empty. If no probe was returned, the test is omitted.
While this test is generally named O, the six probes sent for sequence generation purposes are a special case. Those are inserted into the special OPS test line and take the names O1 through O6 to distinguish which probe packet they relate to. The “O” stands for “options”. Despite the different names, each test O1 through O6 is processed exactly the same way as the other O tests.
TCP initial window size (W, W1–W6) This test simply records the 16-bit TCP window size of the received packet. It is quite effective, since there are more than 80 values that at least one OS is known to send. A down side is that some operating systems have more than a dozen possible values by themselves. This leads to false negative results until we collect all of the possible window sizes used by an operating system.
While this test is generally named W, the six probes sent for sequence generation purposes are a special case. Those are inserted into a special WIN test line and take the names W1 through W6. The window size is recorded for all of the sequence number probes because they differ in TCP MSS option values, which causes some operating systems to advertise a different window size. Despite the different names, each test is processed exactly the same way.
Responsiveness (R) This test simply records whether the target responded to a given probe. Possible values are Y and N. If there is no reply, remaining fields for the test are omitted.
A risk with this test involves probes that are dropped by a firewall. This leads to R=N in the subject fingerprint. Yet the reference fingerprint in nmap-os-db may have R=Y if the target OS usually replies. Thus the firewall could prevent proper OS detection. To reduce this problem, reference fingerprints generally omit the R=Y test from the IE and U1 probes, which are the ones most likely to be dropped. In addition, if Nmap is missing a closed TCP port for a target, it will not set R=N for the T5, T6, or T7 tests even if the port it tries is non-responsive. After all, the lack of a closed port may be because they are all filtered.
IP don’t fragment bit (DF) The IP header contains a single bit which forbids routers from fragmenting a packet. If the packet is too large for routers to handle, they will just have to drop it (and ideally return a “destination unreachable, fragmentation needed” response). This test records Y if the bit is set, and N if it isn’t.
Don’t fragment (ICMP) (DFI) This is simply a modified version of the DF test that is used for the special IE probes. It compares results of the don’t fragment bit for the two ICMP echo request probes sent. It has four possible values, which are enumerated in Table 8.2.
Table 8.2. DFI test values
Value Description N Neither of the ping responses have the DF bit set. S Both responses echo the DF value of the probe. Y Both of the response DF bits are set. O The one remaining other combination—both responses have the DF bit toggled.
IP initial time-to-live (T) IP packets contain a field named time-to-live (TTL) which is decremented every time they traverse a router. If the field reaches zero, the packet must be discarded. This prevents packets from looping endlessly. Because operating systems differ on which TTL they start with, it can be used for Os Detection Techniques. Nmap determines how many hops away it is from the target by examining the ICMP port unreachable response to the U1 probe. That response includes the original IP packet, including the already-decremented TTL field, received by the target. By subtracting that value from our as-sent TTL, we learn how many hops away the machine is. Nmap then adds that hop distance to the probe response TTL to determine what the initial TTL was when that ICMP probe response packet was sent. That initial TTL value is stored in the fingerprint as the T result.
Even though an eight-bit field like TTL can never hold values greater than 0xFF, this test occasionally results in values of 0x100 or higher. This occurs when a system (could be the source, a target, or a system in between) corrupts or otherwise fails to correctly decrement the TTL. It can also occur due to asymmetric routes.
Nmap can also learn from the system interface and routing tables when the hop distance is zero (localhost scan) or one (on the same network segment). This value is used when Nmap prints the hop distance for the user, but it is not used for T result computation.
IP initial time-to-live guess (TG) It is not uncommon for Nmap to receive no response to the U1 probe, which prevents Nmap from learning how many hops away a target is. Firewalls and NAT devices love to block unsolicited UDP packets. But since common TTL values are spread well apart and targets are rarely more than 20 hops away, Nmap can make a pretty good guess anyway. Most systems send packets with an initial TTL of 32, 60, 64, 128, or 255. So the TTL value received in the response is rounded up to the next value out of 32, 64, 128, or 255. 60 is not in that list because it cannot be reliably distinguished from 64. It is rarely seen anyway. The resulting guess is stored in the TG field. This TTL guess field is not printed in a subject fingerprint if the actual TTL (T) value was discovered.
Explicit congestion notification (CC) This test is only used for the ECN probe. That probe is a SYN packet which includes the CWR and ECE congestion control flags. When the response SYN/ACK is received, those flags are examined to set the CC (congestion control) test value as described in Table 8.3.
Table 8.3. CC test values
Value Description Y Only the ECE bit is set (not CWR). This host supports ECN. N Neither of these two bits is set. The target does not support ECN. S Both bits are set. The target does not support ECN, but it echoes back what it thinks is reserved bit. O The one remaining combination of these two bits (other).
TCP miscellaneous quirks (Q) This tests for two quirks that a few implementations have in their TCP stack. The first is that the reserved field in the TCP header (right after the header length) is nonzero. This is particularly likely to happen in response to the ECN test as that one sets a reserved bit in the probe. If this is seen in a packet, an “R” is recorded in the Q string.
The other quirk Nmap tests for is a nonzero urgent pointer field value when the URG flag is not set. This is also particularly likely to be seen in response to the ECN probe, which sets a non-zero urgent field. A “U” is appended to the Q string when this is seen.
The Q string must always be generated in alphabetical order. If no quirks are present, the Q test is empty but still shown.
TCP sequence number (S) This test examines the 32-bit sequence number field in the TCP header. Rather than record the field value as some other tests do, this one examines how it compares to the TCP acknowledgment number from the probe that elicited the response. It then records the appropriate value as shown in Table 8.4.
Table 8.4. S test values
Value Description Z Sequence number is zero. A Sequence number is the same as the acknowledgment number in the probe. A+ Sequence number is the same as the acknowledgment number in the probe plus one. O Sequence number is something else (other).
TCP acknowledgment number (A) This test is the same as S except that it tests how the acknowledgment number in the response compares to the sequence number in the respective probe. The four possible values are given in Table 8.5.
Table 8.5. A test values
Value Description Z Acknowledgment number is zero. S Acknowledgment number is the same as the sequence number in the probe. S+ Acknowledgment number is the same as the sequence number in the probe plus one. O Acknowledgment number is something else (other).
TCP flags (F) This field records the TCP flags in the response. Each letter represents one flag, and they occur in the same order as in a TCP packet (from high-bit on the left, to the low ones). So the value AS represents the ACK and SYN bits set, while the value SA is illegal (wrong order). The possible flags are shown in Table 8.6.
Table 8.6. F test values
Character Flag name Flag byte value E ECN Echo (ECE) 64 U Urgent Data (URG) 32 A Acknowledgment (ACK) 16 P Push (PSH) 8 R Reset (RST) 4 S Synchronize (SYN) 2 F Final (FIN) 1
TCP RST data checksum (RD) Some operating systems return ASCII data such as error messages in reset packets. This is explicitly allowed by section 4.2.2.12 of RFC 1122. When Nmap encounters such data, it performs a CRC32 checksum and reports the results. When there is no data, RD is set to zero. Some of the few operating systems that may return data in their reset packets are HP-UX and versions of Mac OS prior to Mac OS X.
IP total length (IPL) This test records the total length (in octets) of an IP packet. It is only used for the port unreachable response elicited by the U1 test. That length varies by implementation because they are allowed to choose how much data from the original probe to include, as long as they meet the minimum RFC 1122 requirement. That requirement is to include the original IP header and at least eight bytes of data.
Unused port unreachable field nonzero (UN) An ICMP port unreachable message header is eight bytes long, but only the first four are used. RFC 792 states that the last four bytes must be zero. A few implementations (mostly ethernet switches and some specialized embedded devices) set it anyway. The value of those last four bytes is recorded in this field.
Returned probe IP total length value (RIPL) ICMP port unreachable messages (as are sent in response to the U1 probe) are required to include the IP header which generated them. This header should be returned just as they received it, but some implementations send back a corrupted version due to changes they made during IP processing. This test simply records the returned IP total length value. If the correct value of 0x148 (328) is returned, the value G (for good) is stored instead of the actual value.
Returned probe IP ID value (RID) The U1 probe has a static IP ID value of 0x1042. If that value is returned in the port unreachable message, the value G is stored for this test. Otherwise the exact value returned is stored. Some systems, such as Solaris, manipulate IP ID values for raw IP packets that Nmap sends. In such cases, this test is skipped. We have found that some systems, particularly HP and Xerox printers, flip the bytes and return 0x4210 instead.
Integrity of returned probe IP checksum value (RIPCK) The IP checksum is one value that we don’t expect to remain the same when returned in a port unreachable message. After all, each network hop during transit changes the checksum as the TTL is decremented. However, the checksum we receive should match the enclosing IP packet. If it does, the value G (good) is stored for this test. If the returned value is zero, then Z is stored. Otherwise the result is I (invalid).
Integrity of returned probe UDP checksum (RUCK) The UDP header checksum value should be returned exactly as it was sent. If it is, G is recorded for this test. Otherwise the value actually returned is recorded.
Integrity of returned UDP data (RUD) This test checks the integrity of the (possibly truncated) returned UDP payload. If all the payload bytes are the expected ‘C’ (0x43), or if the payload was truncated to zero length, G is recorded; otherwise, I (invalid) is recorded.
ICMP response code (CD) The code value of an ICMP echo reply (type zero) packet is supposed to be zero. But some implementations wrongly send other values, particularly if the echo request has a nonzero code (as one of the IE tests does). The response code values for the two probes are combined into a CD value as described in Table 8.7.
Table 8.7. CD test values
Value Description Z Both code values are zero. S Both code values are the same as in the corresponding probe. When they both use the same non-zero number, it is shown here. O Any other combination.
Usage and Examples The inner workings of OS detection are quite complex, but it is one of the easiest features to use. Simply add -O to your scan options. You may want to also increase the verbosity with -v for even more OS-related details. This is shown in Example 8.1.
Example 8.1. OS detection with verbosity (-O -v)
# nmap -O -v scanme.nmap.org
Starting Nmap ( https://nmap.org ) Nmap scan report for scanme.nmap.org (74.207.244.221) Not shown: 994 closed ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open http 646/tcp filtered ldp 1720/tcp filtered H.323/Q.931 9929/tcp open nping-echo 31337/tcp open Elite Device type: general purpose Running: Linux 2.6.X OS CPE: cpe:/o:linux:linux_kernel:2.6.39 OS details: Linux 2.6.39 Uptime guess: 1.674 days (since Fri Sep 9 12:03:04 2011) Network Distance: 10 hops TCP Sequence Prediction: Difficulty=205 (Good luck!) IP ID Sequence Generation: All zeros
Read data files from: /usr/local/bin/../share/nmap Nmap done: 1 IP address (1 host up) scanned in 5.58 seconds Raw packets sent: 1063 (47.432KB) | Rcvd: 1031 (41.664KB)
Including the -O -v options caused Nmap to generate the following extra line items:
Device type All fingerprints are classified with one or more high-level device types, such as router, printer, firewall, or (as in this case) general purpose. These are further described in the section called “Device and OS classification (Class lines)”. Several device types may be shown, in which case they will be separated with the pipe symbol as in “Device Type: router|firewall”.
Running This field is also related to the OS classification scheme described in the section called “Device and OS classification (Class lines)”. It shows the OS Family (Linux in this case) and OS generation (2.6.X) if available. If there are multiple OS families, they are separated by commas. When Nmap can’t narrow down OS generations to one specific choice, options are separated by the pipe symbol (‘|’) Examples include OpenBSD 3.X, NetBSD 3.X|4.X and Linux 2.4.X|2.5.X|2.6.X.
If Nmap finds too many OS families to print concisely, it will omit this line. When there are no perfect matches, Nmap changes the field to Running (JUST GUESSING) and adds an accuracy percentage (100% is a perfect match) in parentheses after each candidate family name. If no fingerprints are close matches, the line is omitted.
OS CPE This shows a Common Platform Enumeration (CPE) representation of the operating system when available. It may also have a CPE representation of the hardware type. OS CPE begins with cpe:/o and hardware CPE begins with cpe:/h. For more about CPE see the section called “Common Platform Enumeration (CPE)”.
OS details This line gives the detailed description for each fingerprint that matches. While the Device type and Running lines are from predefined enumerated lists that are easy to parse by a computer, the OS details line contains free-form data which is useful to a human reading the report. This can include more exact version numbers, device models, and architectures specific to a given fingerprint. In this example, the only matching fingerprint was Linux 2.6.20-1 ( Fedora Core 5). When there are multiple exact matches, they are comma-separated. If there aren’t any perfect matches, but some close guesses, the field is renamed Aggressive OS guesses and fingerprints are shown followed by a percentage in parentheses which specifies how close each match was.
Uptime guess As part of OS detection, Nmap receives several SYN/ACK TCP packets in a row and checks the headers for a timestamp option. Many operating systems use a simple counter for this which starts at zero at boot time then increments at a constant rate such as twice per second. By looking at several responses, Nmap can determine the current values and rate of increase. Simple linear extrapolation determines boot time. The timestamp algorithm is used for OS detection too (see the section called “TCP timestamp option algorithm (TS)”) since the increment rate on different systems varies from 2 Hz to 1,000 Hz.
The uptime guess is labeled a “guess” because various factors can make it completely inaccurate. Some operating systems do not start the timestamp counter at zero, but initialize it with a random value, making extrapolation to zero meaningless. Even on systems using a simple counter starting at zero, the counter eventually overflows and wraps around. With a 1,000 Hz counter increment rate, the counter resets to zero roughly every 50 days. So a host that has been up for 102 days will appear to have been up only two days. Even with these caveats, the uptime guess is accurate much of the time for most operating systems, so it is printed when available, but only in verbose mode. The uptime guess is omitted if the target gives zeros or no timestamp options in its SYN/ACK packets, or if it does not reply at all. The line is also omitted if Nmap cannot discern the timestamp increment rate or it seems suspicious (like a 30-year uptime).
Network Distance A side effect of one of the OS detection tests allows Nmap to compute how many routers are between it and a target host. The distance is zero when you are scanning localhost, and one for a machine on the same network segment. Each additional router on the path adds one to the hop count. The Network Distance line is not printed in this example, since Nmap omits the line when it cannot be computed (no reply to the relevant probe).
TCP Sequence Prediction Systems with poor TCP initial sequence number generation are vulnerable to blind TCP spoofing attacks. In other words, you can make a full connection to those systems and send (but not receive) data while spoofing a different IP address. The target’s logs will show the spoofed IP, and you can take advantage of any trust relationship between them. This attack was all the rage in the mid-nineties when people commonly used rlogin to allow logins to their account without any password from trusted IP addresses. Kevin Mitnick is alleged to have used this attack to break into Tsutomu Shimomura’s computers in December 1994.
The good news is that hardly anyone uses rlogin anymore, and many operating systems have been fixed to use unpredictable initial sequence numbers as proposed by RFC 1948. For these reasons, this line is only printed in verbose mode. Sadly, many vendors still ship vulnerable operating systems and devices. Even the fixed ones often vary in implementation, which leaves them valuable for OS detection purposes. The class describes the ISN generation algorithm used by the target, and difficulty is a rough estimate of how hard the system makes blind IP spoofing (0 is the easiest). The parenthesized comment is based on the difficulty index and ranges from Trivial joke to Easy, Medium, Formidable, Worthy challenge, and finally Good luck! Further details about sequence tests are provided in the section called “TCP ISN greatest common divisor (GCD)”.
While the rlogin family is mostly a relic of the past, clever attackers can still find effective uses for blind TCP spoofing. For example, it allows for spoofed HTTP requests. You don’t see the results, but just the URL (POST or GET request) can have dramatic side effects. The spoofing allows attackers to hide their identity, frame someone else, or exploit IP address restrictions.
IP ID sequence generation Many systems unwittingly give away sensitive information about their traffic levels based on how they generate the lowly 16-bit ID field in IP packets. This can be abused to spoof a port scan against other systems and for other mischievous purposes discussed in the section called “TCP Idle Scan (-sI)”. This field describes the ID generation algorithm that Nmap was able to discern. More information on how it classifies them is available in the section called “IP ID sequence generation algorithm (TI, CI, II)”. Note that many systems use a different IP ID space for each host they communicate with. In that case, they may appear vulnerable (such as showing the Incremental class) while still being secure against attacks such as the idle scan. For this reason, and because the issue is rarely critical, the IP ID sequence generation line is only printed in verbose mode. If Nmap does not receive sufficient responses during OS detection, it will omit the whole line. The best way to test whether a host is vulnerable to being an idle scan zombie is to test it with -sI.
While TCP fingerprinting is a powerful method for OS detection, interrogating open ports for clues is another effective approach. Some applications, such as Microsoft IIS, only run on a single platform (thus giving it away), while many other apps divulge their platform in overly verbose banner messages. Adding the -sV option enables Nmap version detection, which is trained to look for these clues (among others). In Example 8.2, Nmap catches the platform details from an FTP server.
Example 8.2. Using version scan to detect the OS
# nmap -sV -O -v 129.128.X.XX
Starting Nmap ( https://nmap.org ) Nmap scan report for [hostname] (129.128.X.XX) Not shown: 994 closed ports PORT STATE SERVICE VERSION 21/tcp open ftp HP-UX 10.x ftpd 4.1 22/tcp open ssh OpenSSH 3.7.1p1 (protocol 1.99) 111/tcp open rpc 445/tcp filtered microsoft-ds 1526/tcp open oracle-tns Oracle TNS Listener 32775/tcp open rpc No exact OS matches for host TCP Sequence Prediction: Class=truly random Difficulty=9999999 (Good luck!) IP ID Sequence Generation: Incremental Service Info: OS: HP-UX
In this example, the line “No exact OS matches for host” means that TCP/IP fingerprinting failed to find an exact match. Fortunately, the Service Info field a few lines down discloses that the OS is HP-UX. If several operating systems were detected (which can happen with NAT gateway boxes that redirect ports to several different machines), the field would be OSs and the values would be comma separated. The Service Info line can also contain hostnames and device types found during the version scan. The focus of this chapter is on TCP/IP fingerprinting though, since version detection was covered in Chapter 7, Service and Application Version Detection.
With two effective Os Detection Techniques available, which one should you use? The best answer is usually both. In some cases, such as a proxy firewall forwarding to an application on another host, the answers may legitimately differ. TCP/IP fingerprinting will identify the proxy while version scanning will generally detect the server running the proxied application. Even when no proxying or port forwarding is involved, using both techniques is beneficial. If they come out the same, that makes the results more credible. If they come out wildly different, investigate further to determine what is going on before relying on either. Since OS and version detection go together so well, the -A option enables them both.
OS detection is far more effective if at least one open and one closed TCP port are found. Set the –osscan-limit option and Nmap will not even try OS detection against hosts which do not meet this criteria. This can save substantial time, particularly on -Pn scans against many hosts. You still need to enable OS detection with -O (or -A) for the –osscan-limit option to have any effect.
Another OS detection option is –osscan-guess. When Nmap is unable to detect a perfect OS match, it sometimes offers up near-matches as possibilities. The match has to be very close for Nmap to do this by default. If you specify this option (or the equivalent –fuzzy option), Nmap will guess more aggressively. Nmap still tells you when an imperfect match is found and display its confidence level (percentage) for each guess.
When Nmap performs OS detection against a target and fails to find a perfect match, it usually repeats the attempt. By default, Nmap tries five times if conditions are favorable for OS fingerprint submission, and twice when conditions aren’t so good. The –max-os-tries option lets you change this maximum number of OS detection tries. Lowering it (usually to 1) speeds Nmap up, though you miss out on retries which could potentially identify the OS. Alternatively, a high value may be set to allow even more retries when conditions are favorable. This is rarely done, except to generate better fingerprints for submission and integration into the Nmap OS database.
Like just about every other part of Nmap, results ultimately come from the target machine itself. While rare, systems are occasionally configured to confuse or mislead Nmap. Several programs have even been developed specifically to trick Nmap OS detection (see the section called “OS Spoofing”). Your best bet is to use numerous reconnaissance methods to explore a network, and don’t trust any one of them.
TCP/IP fingerprinting requires collecting detailed information about the target’s IP stack. The most commonly useful results, such as TTL information, are printed to Nmap output whenever they are obtained. Slightly less pertinent information, such as IP ID sequence generation and TCP sequence prediction difficulty, is only printed in verbose mode. But if you want all of the IP stack details that Nmap collected, you can find it in a compact form called a subject fingerprint. Nmap sometimes prints this (for user submission purposes) when it doesn’t recognize a host. You can also force Nmap to print it (in normal, interactive, and XML formats) by enabling debugging with (-d). Then read the section called “Understanding an Nmap Fingerprint” to interpret it.
P0f brief overview of how tool does os detection
p0f – https://lcamtuf.coredump.cx/p0f3/
P0f is a tool that utilizes an array of sophisticated, purely passive traffic fingerprinting mechanisms to identify the players behind any incidental TCP/IP communications (often as little as a single normal SYN) without interfering in any way. Version 3 is a complete rewrite of the original codebase, incorporating a significant number of improvements to network-level fingerprinting, and introducing the ability to reason about application-level payloads (e.g., HTTP). Some of p0f’s capabilities include:
Highly scalable and extremely fast identification of the operating system and software on both endpoints of a vanilla TCP connection – especially in settings where NMap probes are blocked, too slow, unreliable, or would simply set off alarms.Measurement of system uptime and network hookup, distance (including topology behind NAT or packet filters), user language preferences, and so on. Automated detection of connection sharing / NAT, load balancing, and application-level proxying setups. Detection of clients and servers that forge declarative statements such as X-Mailer or User-Agent. The tool can be operated in the foreground or as a daemon, and offers a simple real-time API for third-party components that wish to obtain additional information about the actors they are talking to. Common uses for p0f include reconnaissance during penetration tests; routine network monitoring; detection of unauthorized network interconnects in corporate environments; providing signals for abuse-prevention tools; and miscellanous forensics.
p0f is a passive TCP/IP stack fingerprinting tool. p0f can attempt to identify the system running on machines that send network traffic to the box it is running on, or to a machine that shares a medium with the machine it is running on. p0f can also assist in analysing other aspects of the remote system
By inspecting network traffic passively, p0f can attempt to identify the operating systems on remote machines that send TCP packets to the detecting machine’s network interface, or to a physical subnet that the detecting machine can listen on.[1] Since version 3, p0f is also able to deduce aspects of the remote system by inspecting application-level HTTP messages.[1]
p0f can also check for firewall presence. It can estimate the distance to a remote system and calculate its uptime. It also guesses the remote system’s means of connecting to the network ( DSL, OC3, etc.).[1]
Unlike tools like nmap, p0f does not generate traffic.[1] Instead, it determines the operating system of the remote host by analyzing certain fields in the captured packets. This can have benefits in environments where actively creating network traffic would cause unhelpful side effects. In particular, the remote system will not be able to detect the packet capture and inspection.
Usage Signatures used for packet inspection are stored in a simple text file.[2] This allows them to be modified without recompiling p0f. The user is allowed to use a different fingerprinting file by selecting another one at run time.
p0f does not have a graphical user interface. It is instead run from the command line prompt.
============================= p0f v3: passive fingerprinter =============================
https://lcamtuf.coredump.cx/p0f3.shtml
Copyright (C) 2012 by Michal Zalewski <lcamtuf@coredump.cx>
P0f is a tool that utilizes an array of sophisticated, purely passive traffic fingerprinting mechanisms to identify the players behind any incidental TCP/IP communications (often as little as a single normal SYN) without interfering in any way.
Some of its capabilities include:
– Highly scalable and extremely fast identification of the operating system and software on both endpoints of a vanilla TCP connection – especially in settings where NMap probes are blocked, too slow, unreliable, or would simply set off alarms,
– Measurement of system uptime and network hookup, distance (including topology behind NAT or packet filters), and so on.
– Automated detection of connection sharing / NAT, load balancing, and application-level proxying setups.
– Detection of dishonest clients / servers that forge declarative statements such as X-Mailer or User-Agent.
The tool can be operated in the foreground or as a daemon, and offers a simple real-time API for third-party components that wish to obtain additional information about the actors they are talking to.
Common uses for p0f include reconnaissance during penetration tests; routine network monitoring; detection of unauthorized network interconnects in corporate environments; providing signals for abuse-prevention tools; and miscellanous forensics.
A snippet of typical p0f output may look like this:
.-[ 1.2.3.4/1524 -> 4.3.2.1/80 (syn) ]- | | client = 1.2.3.4 | os = Windows XP | dist = 8 | params = none | raw_sig = 4:120+8:0:1452:65535,0:mss,nop,nop,sok:df,id+:0 | `—-
.-[ 1.2.3.4/1524 -> 4.3.2.1/80 (syn+ack) ]- | | server = 4.3.2.1 | os = Linux 3.x | dist = 0 | params = none | raw_sig = 4:64+0:0:1460:mss*10,0:mss,nop,nop,sok:df:0 | `—-
.-[ 1.2.3.4/1524 -> 4.3.2.1/80 (mtu) ]- | | client = 1.2.3.4 | link = DSL | raw_mtu = 1492 | `—-
.-[ 1.2.3.4/1524 -> 4.3.2.1/80 (uptime) ]- | | client = 1.2.3.4 | uptime = 0 days 11 hrs 16 min (modulo 198 days) | raw_freq = 250.00 Hz | `—-
A live demonstration can be seen here:
https://lcamtuf.coredump.cx/p0f3/
A vast majority of metrics used by p0f were invented specifically for this tool, and include data extracted from IPv4 and IPv6 headers, TCP headers, the dynamics of the TCP handshake, and the contents of application-level payloads.
For TCP/IP, the tool fingerprints the client-originating SYN packet and the first SYN+ACK response from the server, paying attention to factors such as the ordering of TCP options, the relation between maximum segment size and window size, the progression of TCP timestamps, and the state of about a dozen possible implementation quirks (e.g. non-zero values in “must be zero” fields).
The metrics used for application-level traffic vary from one module to another; where possible, the tool relies on signals such as the ordering or syntax of HTTP headers or SMTP commands, rather than any declarative statements such as User-Agent. Application-level fingerprinting modules currently support HTTP. Before the tool leaves “beta”, I want to add SMTP and FTP. Other protocols, such as FTP, POP3, IMAP, SSH, and SSL, may follow.
The list of all the measured parameters is reviewed in section 5 later on. Some of the analysis also happens on a higher level: inconsistencies in the data collected from various sources, or in the data from the same source obtained over time, may be indicative of address translation, proxying, or just plain trickery. For example, a system where TCP timestamps jump back and forth, or where TTLs and MTUs change subtly, is probably a NAT device.
Os Detection Techniques – P0f Fingerprint database
Whenever p0f obtains a fingerprint from the observed traffic, it defers to the data read from p0f.fp to identify the operating system and obtain some ancillary data needed for other analysis tasks. The fingerprint database is a simple text file where lines starting with ; are ignored.
== Module specification ==
The file is split into sections based on the type of traffic the fingerprints apply to. Section identifiers are enclosed in square brackets, like so:
[module:direction]
module – the name of the fingerprinting module (e.g. ‘tcp’ or ‘http’).
direction – the direction of fingerprinted traffic: ‘request’ (from client to server) or ‘response’ (from server to client).
For the TCP module, ‘client’ matches the initial SYN; and ‘server’ matches SYN+ACK.
The ‘direction’ part is omitted for MTU signatures, as they work equally well both ways.
== Signature groups ==
The actual signatures must be preceeded by an ‘label’ line, describing the fingerprinted software:
label = type:class:name:flavor
type – some signatures in p0f.fp offer broad, last-resort matching for less researched corner cases. The goal there is to give an answer slightly better than “unknown”, but less precise than what the user may be expecting.
Normal, reasonably specific signatures that can’t be radically improved should have their type specified as ‘s’; while generic, last-resort ones should be tagged with ‘g’.
Note that generic signatures are considered only if no specific matches are found in the database.
class – the tool needs to distinguish between OS-identifying signatures (only one of which should be matched for any given host) and signatures that just identify user applications (many of which may be seen concurrently).
To assist with this, OS-specific signatures should specify the OS architecture family here (e.g., ‘win’, ‘unix’, ‘cisco’); while application-related sigs (NMap, MSIE, Apache) should use a special value of ‘!’.
Most TCP signatures are OS-specific, and should have OS family defined. Other signatures, such as HTTP, should use ‘!’ unless the fingerprinted component is deeply intertwined with the platform (e.g., Windows Update).
NOTE: To avoid variations (e.g. ‘win’ and ‘windows’ or ‘unix’ and ‘linux’), all classes need to be pre-registered using a ‘classes’ directive, seen near the beginning of p0f.fp.
name – a human-readable short name for what the fingerprint actually helps identify – say, ‘Linux’, ‘Sendmail’, or ‘NMap’. The tool doesn’t care about the exact value, but requires consistency – so don’t switch between ‘Internet Explorer’ and ‘MSIE’, or ‘MacOS’ and ‘Mac OS’.
flavor – anything you want to say to further qualify the observation. Can be the version of the identified software, or a description of what the application seems to be doing (e.g. ‘SYN scan’ for NMap).
NOTE: Don’t be too specific: if you have a signature for Apache 2.2.16, but have no reason to suspect that other recent versions behave in a radically different way, just say ‘2.x’.
P0f uses labels to group similar signatures that may be plausibly generated by the same system or application, and should not be considered a strong signal for NAT Os Detection Techniques.
To further assist the tool in deciding which OS and application combinations are reasonable, and which ones are indicative of foul play, any ‘label’ line for applications (class ‘!’) should be followed by a comma-delimited list of OS names or @-prefixed OS architecture classes on which this software is known to be used on. For example:
label = s:!:Uncle John’s Networked ls Utility:2.3.0.1 sys = Linux,FreeBSD,OpenBSD
…or:
label = s:!:Mom’s Homestyle Browser:1.x sys = @unix,@win
The label can be followed by any number of module-specific signatures; all of them will be linked to the most recent label, and will be reported the same way.
All sections except for ‘name’ are omitted for [mtu] signatures, which do not convey any OS-specific information, and just describe link types.
== MTU signatures ==
Many operating systems derive the maximum segment size specified in TCP options from the MTU of their network interface; that value, in turn, normally depends on the design of the link-layer protocol. A different MTU is associated with PPPoE, a different one with IPSec, and a different one with Juniper VPN.
The format of the signatures in the [mtu] section is exceedingly simple, consisting just of a description and a list of values:
label = Ethernet sig = 1500
These will be matched for any wildcard MSS TCP packets (see below) not generated by userspace TCP tools.
== TCP Os Detection Techniques signatures ==
For TCP traffic, signature layout is as follows:
sig = ver:ittl:olen:mss:wsize,scale:olayout:quirks:pclass
ver – signature for IPv4 (‘4’), IPv6 (‘6’), or both (‘*’).
NEW SIGNATURES: P0f documents the protocol observed on the wire, but you should replace it with ‘*’ unless you have observed some actual differences between IPv4 and IPv6 traffic, or unless the software supports only one of these versions to begin with.
ittl – initial TTL used by the OS. Almost all operating systems use 64, 128, or 255; ancient versions of Windows sometimes used 32, and several obscure systems sometimes resort to odd values such as 60.
NEW SIGNATURES: P0f will usually suggest something, using the format of ‘observed_ttl+distance’ (e.g. 54+10). Consider using traceroute to check that the distance is accurate, then sum up the values. If initial TTL can’t be guessed, p0f will output ‘nnn+?’, and you need to use traceroute to estimate the ‘?’.
A handful of userspace tools will generate random TTLs. In these cases, determine maximum initial TTL and then add a – suffix to the value to avoid confusion.
olen – length of IPv4 options or IPv6 extension headers. Usually zero for normal IPv4 traffic; always zero for IPv6 due to the limitations of libpcap.
NEW SIGNATURES: Copy p0f output literally.
mss – maximum segment size, if specified in TCP options. Special value of ‘*’ can be used to denote that MSS varies depending on the parameters of sender’s network link, and should not be a part of the signature. In this case, MSS will be used to guess the type of network hookup according to the [mtu] rules.
NEW SIGNATURES: Use ‘*’ for any commodity OSes where MSS is around 1300 – 1500, unless you know for sure that it’s fixed. If the value is outside that range, you can probably copy it literally.
wsize – window size. Can be expressed as a fixed value, but many operating systems set it to a multiple of MSS or MTU, or a multiple of some random integer. P0f automatically detects these cases, and allows notation such as ‘mss*4’, ‘mtu*4’, or ‘%8192’ to be used. Wilcard (‘*’) is possible too.
NEW SIGNATURES: Copy p0f output literally. If frequent variations are seen, look for obvious patterns. If there are no patterns, ‘*’ is a possible alternative.
scale – window scaling factor, if specified in TCP options. Fixed value or ‘*’.
NEW SIGNATURES: Copy literally, unless the value varies randomly. Many systems alter between 2 or 3 scaling factors, in which case, it’s better to have several ‘sig’ lines, rather than a wildcard.
olayout – comma-delimited layout and ordering of TCP options, if any. This is one of the most valuable TCP fingerprinting signals. Supported values:
eol+n – explicit end of options, followed by n bytes of padding nop – no-op option mss – maximum segment size ws – window scaling sok – selective ACK permitted sack – selective ACK (should not be seen) ts – timestamp ?n – unknown option ID n
NEW SIGNATURES: Copy this string literally.
quirks – comma-delimited properties and quirks observed in IP or TCP headers:
df – “don’t fragment” set (probably PMTUD); ignored for IPv6 id+ – DF set but IPID non-zero; ignored for IPv6 id- – DF not set but IPID is zero; ignored for IPv6 ecn – explicit congestion notification support 0+ – “must be zero” field not zero; ignored for IPv6 flow – non-zero IPv6 flow ID; ignored for IPv4
seq- – sequence number is zero ack+ – ACK number is non-zero, but ACK flag not set ack- – ACK number is zero, but ACK flag set uptr+ – URG pointer is non-zero, but URG flag not set urgf+ – URG flag used pushf+ – PUSH flag used
ts1- – own timestamp specified as zero ts2+ – non-zero peer timestamp on initial SYN opt+ – trailing non-zero data in options segment exws – excessive window scaling factor (> 14) bad – malformed TCP options
If a signature scoped to both IPv4 and IPv6 contains quirks valid for just one of these protocols, such quirks will be ignored for on packets using the other protocol. For example, any combination of ‘df’, ‘id+’, and ‘id-‘ is always matched by any IPv6 packet.
NEW SIGNATURES: Copy literally.
pclass – payload size classification: ‘0’ for zero, ‘+’ for non-zero, ‘*’ for any. The packets we fingerprint right now normally have no payloads, but some corner cases exist.
NEW SIGNATURES: Copy literally.
NOTE: The TCP module allows some fuzziness when an exact match can’t be found: ‘df’ and ‘id+’ quirks are allowed to disappear; ‘id-‘ or ‘ecn’ may appear; and TTLs can change.
To gather new SYN (‘request’) signatures, simply connect to the fingerprinted system, and p0f will provide you with the necessary data. To gather SYN+ACK (‘response’) signatures, you should use the bundled p0f-sendsyn utility while p0f is running in the background; creating them manually is not advisable.
== HTTP signatures ==
A special directive should appear at the beginning of the [https:request] section, structured the following way:
ua_os = Linux,Windows,iOS=[iPad],iOS=[iPhone],Mac OS X,…
This list should specify OS names that should be looked for within the User-Agent string if the string is otherwise deemed to be honest. This input is not used for fingerprinting, but aids NAT detection in some useful ways.
The names have to match the names used in ‘sig’ specifiers across p0f.fp. If a particular name used by p0f differs from what typically appears in User-Agent, the name=[string] syntax may be used to define any number of aliases.
Other than that, HTTP signatures for GET and HEAD requests have the following layout:
sig = ver:horder:habsent:expsw
ver – 0 for HTTP/1.0, 1 for HTTP/1.1, or ‘*’ for any.
NEW SIGNATURES: Copy the value literally, unless you have a specific reason to do otherwise.
horder – comma-separated, ordered list of headers that should appear in matching traffic. Substrings to match within each of these headers may be specified using a name=[value] notation.
The signature will be matched even if other headers appear in between, as long as the list itself is matched in the specified sequence.
Headers that usually do appear in the traffic, but may go away (e.g. Accept-Language if the user has no languages defined, or Referer if no referring site exists) should be prefixed with ‘?’, e.g. “?Referer”. P0f will accept their disappearance, but will not allow them to appear at any other location.
NEW SIGNATURES: Review the list and remove any headers that appear to be irrelevant to the fingerprinted software, and mark transient ones with ‘?’. Remove header values that do not add anything to the signature, or are request- or user-specific. In particular, pay attention to Accept, Accept-Language, and Accept-Charset, as they are highly specific to request type and user settings.
P0f automatically removes some headers, prefixes others with ‘?’, and inhibits the value of fields such as ‘Referer’ or ‘Cookie’ – but this is not a substitute for manual review.
NOTE: Server signatures may differ depending on the request (HTTP/1.1 versus 1.0, keep-alive versus one-shot, etc) and on the returned resource (e.g., CGI versus static content). Play around, browse to several URLs, also try curl and wget.
habsent – comma-separated list of headers that must *not* appear in matching traffic. This is particularly useful for noting the absence of standard headers (e.g. ‘Host’), or for differentiating between otherwise very similar signatures.
NEW SIGNATURES: P0f will automatically highlight the absence of any normally present headers; other entries may be added where necessary.
expsw – expected substring in ‘User-Agent’ or ‘Server’. This is not used to match traffic, and merely serves to detect dishonest software. If you want to explicitly match User-Agent, you need to do this in the ‘horder’ section, e.g.:
User-Agent=[Firefox]
Any of these sections sections except for ‘ver’ may be blank.
There are many protocol-level quirks that p0f could be detecting – for example, the use of non-standard newlines, or missing or extra spacing between header field names and values. There is also some information to be gathered from responses to OPTIONS or POST. That said, it does not seem to be worth the effort: the protocol is so verbose, and implemented so arbitrarily, that we are getting more than enough information just with a simple GET / HEAD fingerprint.
== SMTP signatures ==
*** NOT IMPLEMENTED YET ***
== FTP signatures ==
*** NOT IMPLEMENTED YET ***
6. Os Detection Techniques – NAT detection
In addition to fairly straightforward measurements of intrinsic properties of a single TCP session, p0f also tries to compare signatures across sessions to detect client-side connection sharing (NAT, HTTP proxies) or server-side load balancing.
This is done in two steps: the first significant deviation usually prompts a “host change” entry (which may be also indicative of multi-boot, address reuse, or other one-off events); and a persistent pattern of changes prompts an “ip sharing” notification later on.
All of these messages are accompanied by a set of reason codes:
os_sig – the OS detected right now doesn’t match the OS detected earlier on.
sig_diff – no definite OS detection data available, but protocol-level characteristics have changed drastically (e.g., different TCP option layout).
app_vs_os – the application detected running on the host is not supposed to work on the host’s operating system.
x_known – the signature progressed from known to unknown, or vice versa.
The following additional codes are specific to TCP:
tstamp – TCP timestamps went back or jumped forward.
ttl – TTL values have changed.
port – source port number has decreased.
mtu – system MTU has changed.
fuzzy – the precision with which a TCP signature is matched has changed.
The following code is also issued by the HTTP module:
via – data explicitly includes Via / X-Forwarded-For.
us_vs_os – OS fingerprint doesn’t match User-Agent data, and the User-Agent value otherwise looks honest.
app_srv_lb – server application signatures change, suggesting load balancing.
date – server-advertised date changes inconsistently.
Different reasons have different weights, balanced to keep p0f very sensitive even to very homogenous environments behind NAT. If you end up seeing false positives or other detection problems in your environment, please let me know!
sources:
p0f man page nmap man page RFC 791 (IP) https://tools.ietf.org/html/rfc791 RFC 793 (TCP) https://tools.ietf.org/html/rfc793 RFC 826 (ARP) https://tools.ietf.org/html/rfc826
https://en.wikipedia.org/wiki/MAC_address Ali, S., Heriyanto, T. and Allen, L. (2014) Kali Linux: assuring security by penetration testing. Birmingham: Packt Publ. Allen, J. M. (2019) SANS Institute pp.1–49. Anderson, B. and McGrew, D. (2017) OS Fingerprinting: New Techniques and a Study of Information Gain and Obfuscation. arXiv.org. Burroni, J. and Sarraute, C. (2010) Outrepasser les limites des techniques classiques de Prise d’Empreintes grace aux Reseaux de Neurones. arXiv.org. Fyodor (2013) Nmap Network Scanning Official Nmap Project Guide to Network Discovery and Security Scanning pp.1–465. Fyodor (2019a) nmap fingerprinting format [Online]. Available: https://nmap.org/book/osdetect-fingerprint-format.html [Accessed 2 Jun 2019a]. Fyodor (2019b) nmap os detection methods [Online]. Available: https://nmap.org/book/osdetect-methods.html [Accessed 2 Jun 2019b]. Kollmann, E. (2005) Chatter on the Wire: pp.1–46. Kollmann, E. (2019) bh-japan-laporte-kollmann-v8. In:. Tao, K., Li, J. and Sampalli, S. (2009) Detection of Spoofed MAC Addresses in 802.11 Wireless Networks. E-business and Telecommunications. Vol.2 (Chapter 15), pp.201–.
https://www.netresec.com/?page=Blog&month=2011-11&post=Passive-OS-Fingerprinting https://en.wikipedia.org/wiki/TCP/IP_stack_fingerprinting https://phrack.org/issues/54/9.html#article https://www.ietf.org/rfc/rfc2132.txt https://www.juniper.net/documentation/en_US/junose15.1/topics/concept/dhcp-relay-option-60-strings.html
https://subinsb.com/default-device-ttl-values/ https://securitytrails.com/blog/cybersecurity-fingerprinting https://forensicswiki.org/wiki/OS_fingerprinting https://en.wikipedia.org/wiki/Zero-configuration_networking#Service_discovery https://en.wikipedia.org/wiki/Service_discovery https://en.wikipedia.org/wiki/Server_Message_Block https://en.wikipedia.org/wiki/List_of_products_that_support_SMB https://en.wikipedia.org/wiki/NetBIOS https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol https://en.wikipedia.org/wiki/User_agent
Leave a Reply
You must be logged in to post a comment.