
Machine Learning is an exciting field that’s revolutionizing every industry. It’s so easy to get started with Machine Learning, but it can be hard to know where to start. This blog post will give you an introduction to machine learning. It contains a brief introduction to supervised and unsupervised training. Towards the end there is a list of common algorithms and how they work.
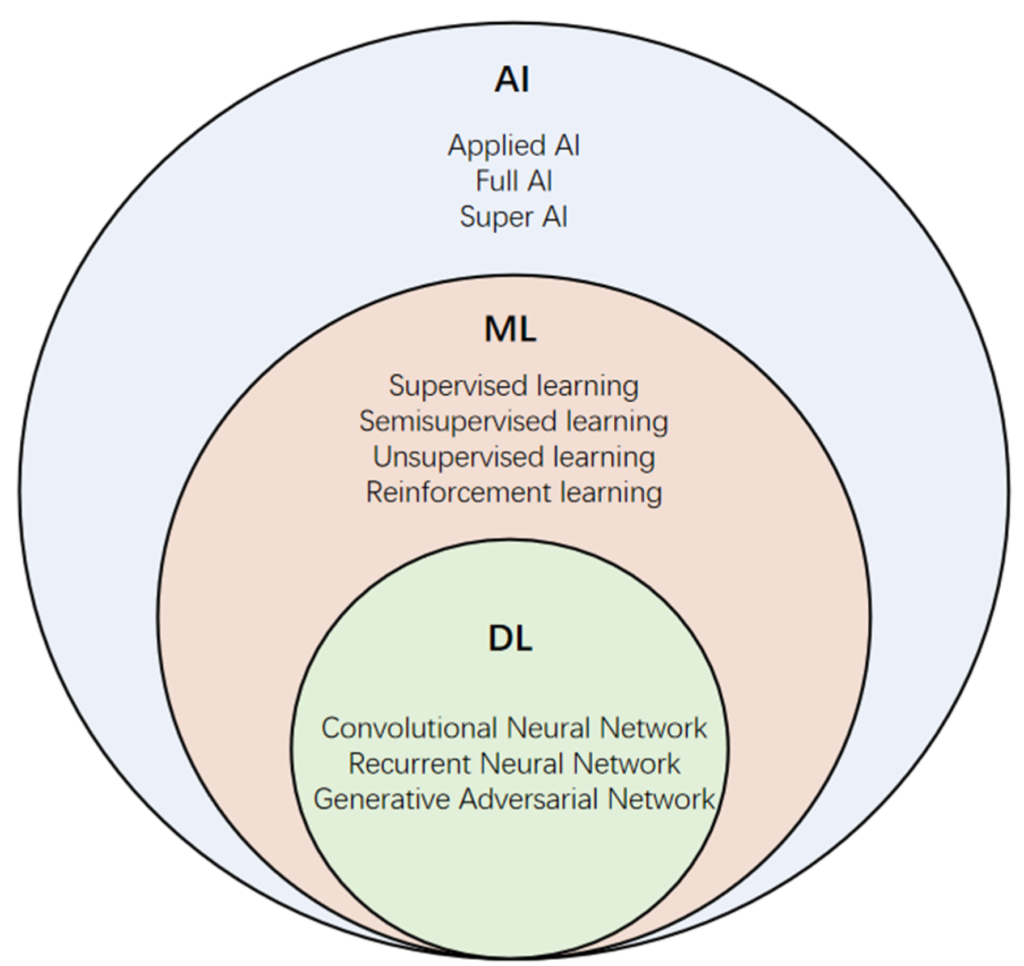
What is AI? An Introduction to Artificial Intelligence. AI stands for artificial intelligence. Artificial intelligence is a branch of computer science. AI aims to make computer systems intelligent. To be able to perceive their environment and take appropriate action. Intelligence is the ability of an agent (a program) to achieve goals in a wide range of environments. This is achieved by learning from experience and understanding natural language instructions.
Machine learning is the process of using computers to make predictions about data. Choosing the correct algorithm and confirming the algorithm behaves accordingly is key.
Supervised and unsupervised training
Supervised learning involves training a model using labelled data. This is useful for situations where you have a large amount of labelled data. The training data is collated by a human and verified as being correct before training the model. Once the model is trained it can process data that has not been validated by a human and produce results.
Supervised machine learning is the process of training a model on a set of known data examples. In supervised learning, you first create a model based on your training dataset (the set of known examples). Then you use this model to make predictions on new data sets. The goal is to use the model to predict how well an unknown set of examples will perform given their attributes (e.g., age).
Unsupervised learning involves training a model with unlabelled or unstructured data. This is useful when there’s no way for humans to tell if their data has been correctly classified.
Unsupervised machine learning involves training without having access to any labeled training examples. This type of learning is useful when there are no attributes associated with each example. it allows us to learn patterns in large amounts of data without having any labels or rules about what those patterns mean.
Common algorithms in supervised and unsupervised machine learning include:
- K-nearest neighbors (kNN)
- SVM classifiers
- Tree-based methods – Decision trees, Bayesian networks
- Neural networks (NN).
K-nearest neighbors
K-nearest neighbors (kNN) are a supervised learning classification algorithm. kNN uses the average distance between each data point and the label of its nearest neighbours.
kNN is often used in machine learning because it’s easy to calculate and use. kNN can also be problematic because there are many ways to measure distance.
For example: Using a distance metric like Euclidean distance: Your training set might include points that are far from their neighbours in the dataset. Those points will end up assigned to a different class than other points in your training set that have similar characteristics.
K-nearest neighbors (kNN) is a machine learning technique that uses data to predict a target value. It uses the distance between each point in your dataset and the nearest point on the target.
You can use kNN to predict the value of a new input or output based on an existing dataset; it’s often used as a form of regression in ML.
SVM classifiers
SVM classifiers are used to classify data into different categories, such as spam or not spam. They use a decision tree algorithm to build their model and then use it to classify new data points.
Support Vector Machines (SVM) are machine learning algorithms that are used for classification tasks. An SVM uses hyperplanes to divide data into two groups (called classes), where each class has its own set of features that define it. The hyperplane separates these features by their values on each side so that there is minimal overlap between them. This helps us determine which feature values are most important for determining which class each individual belongs in; when we train an SVM model on our training data set, it learns how best to separate each point into its own category based on what makes sense for its characteristics compared
Decision trees
Decision trees are most commonly used for classification problems because they’re easy to understand and interpret. These trees are built from leaf nodes (“decision” nodes) which correspond with specific values (or labels). The leaves on these trees will have different probabilities assigned based on how likely they are given those labels.
Decision trees are a type of unsupervised learning algorithm that can be used to process large amounts of data without needing any training data at all–instead, they learn automatically by analyzing how different features interact with each other. Decision trees work well when there are lots of variables involved; however, they’re not very good when there aren’t many variables present (as with most problems involving ML).
Bayesian networks
Bayesian networks are similar to decision trees in that they both use probabilistic models but they differ in how they arrive at their conclusions–Bayesian networks use Bayes’ theorem while decision trees don’t need any additional information beyond what’s already been collected!
Bayesian networks are another type of unsupervised learning algorithm that uses Bayes’ theorem to make predictions about future events based on past events or observations from other sources within a system or network; this allows us to create models
Neural networks (NNs)
Neural Networks are a class of machine learning models inspired by the structure and function of biological neurons in the brain. They are used to model complex, non-linear relationships between inputs and outputs in a wide range of applications such as image recognition, natural language processing, and speech recognition.
Neural Networks consist of layers of interconnected nodes, called neurons, which are organized into input, output, and hidden layers. The input layer receives the input data, and the output layer produces the output. The hidden layers perform complex computations by applying weights to the inputs and passing the result through an activation function.
The weights in the network are learned during the training process, which involves feeding input data into the network, computing the output, and comparing it to the desired output. The difference between the output and the desired output is used to adjust the weights to improve the accuracy of the network.
Neural Networks can be further categorized into different types based on their architecture, such as Feedforward Neural Networks, Convolutional Neural Networks (CNNs), and Recurrent Neural Networks (RNNs). Each type is designed to handle specific types of data and tasks.
Feedforward Neural Networks are the most basic type and are used for tasks such as classification and regression. CNNs are commonly used for image and video recognition tasks. RNNs are used for processing sequential data, such as time-series data or natural language.
Overall, Neural Networks are powerful and flexible tools that can learn complex patterns and relationships in data, making them a crucial component of modern machine learning.
Leave a Reply
You must be logged in to post a comment.